站长注:AI图片生成常见问题的实用解决方法,包含API调用失败、图片质量差、成本超标等问题的快速解决技巧
使用API批量生成图片时遇到问题了?无论是API调用失败、图片质量不理想,还是成本超出预期,每个问题都有对应的解决方法。掌握系统化的问题排查流程,可以快速定位问题根源,找到最优解决方案,让你的API批量图片生成变得稳定高效。
建议到 API易 注册免费账号(新用户送体验额度),可以跟着文章实际操作验证解决方法。
AI图像生成问题分类体系
使用API批量生成图片时,问题通常可以分为四大类别:技术性问题、质量性问题、效率性问题和成本性问题。每类问题都有其特定的排查方法和解决策略。
掌握问题分类是快速解决API调用问题的关键。正确的问题归类能够帮助我们快速缩小排查范围,避免无效的尝试,直接定位到最可能的解决方案。
批量API调用时,多个问题往往会同时出现,需要我们具备系统性的思维来逐一解决,并建立有效的预防机制。
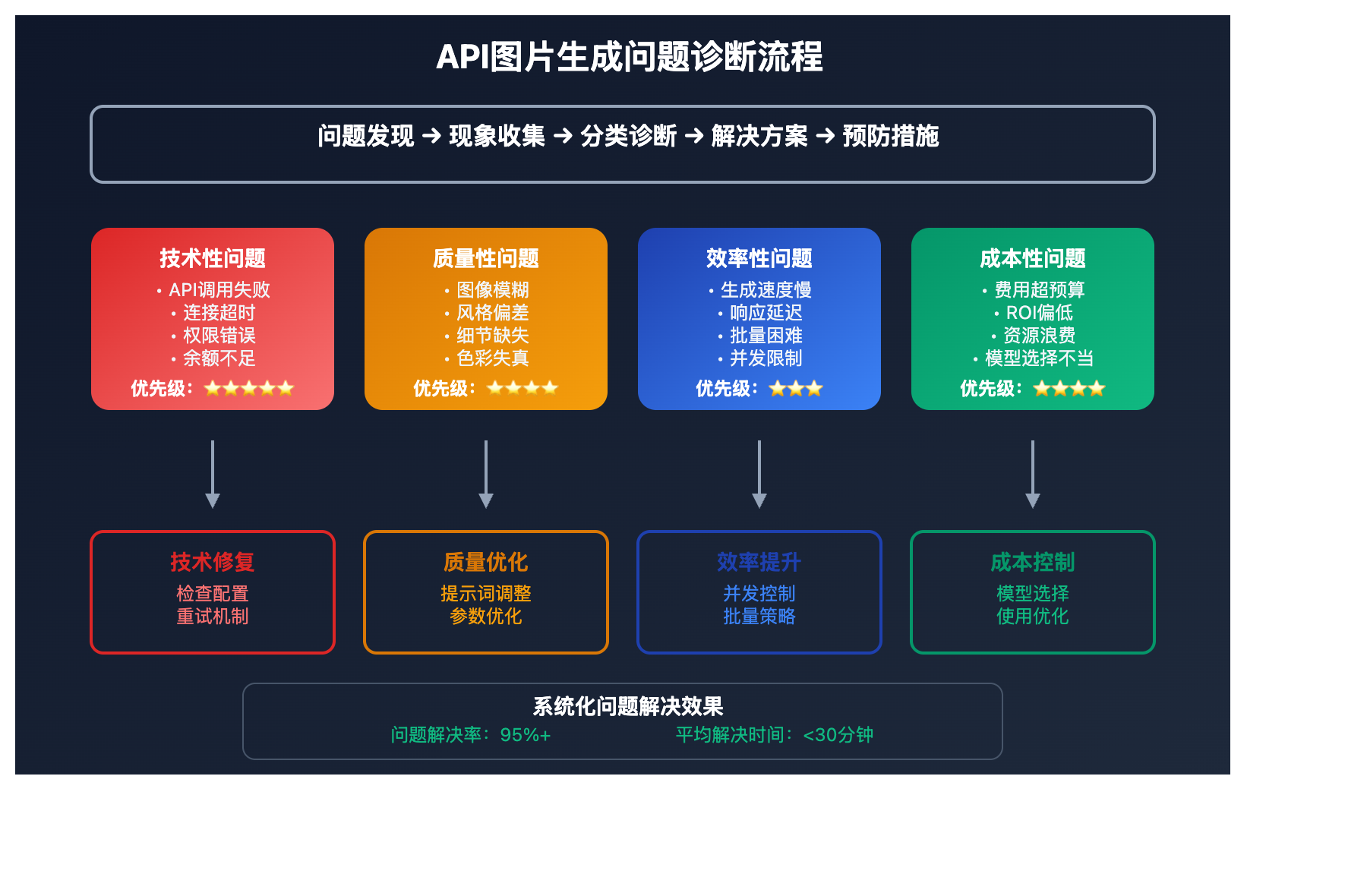
图像生成问题诊断矩阵
以下是 AI图像生成问题 的系统化诊断框架:
| 问题类别 | 主要症状 | 常见原因 | 解决优先级 |
|---|---|---|---|
| 技术性问题 | 请求失败、连接超时、权限错误 | API配置、网络环境、账户状态 | ⭐⭐⭐⭐⭐ |
| 质量性问题 | 图像模糊、风格偏差、细节缺失 | 提示词设计、模型选择、参数设置 | ⭐⭐⭐⭐ |
| 效率性问题 | 生成速度慢、响应延迟、批量处理困难 | 并发设置、请求策略、资源配置 | ⭐⭐⭐⭐ |
| 成本性问题 | 费用超预算、ROI偏低、资源浪费 | 模型选择、使用策略、流程优化 | ⭐⭐⭐⭐⭐ |
🔥 问题排查通用流程
第一阶段:问题现象收集
在开始排查之前,系统收集问题信息至关重要:
- 错误信息记录:完整保存API返回的错误代码和描述
- 环境状态确认:检查网络连接、API密钥、账户余额
- 复现条件分析:记录问题出现的具体条件和触发因素
- 影响范围评估:确定问题是偶发性还是系统性
第二阶段:问题分类定位
根据症状表现,快速将问题归类到对应的类别:
- 技术性问题:通常有明确的错误代码,问题重现性强
- 质量性问题:生成能完成但结果不符合预期
- 效率性问题:功能正常但性能表现不佳
- 成本性问题:费用消耗超出预期或ROI不理想

分类问题解决方案
针对不同类别的问题,我们需要采用相应的解决策略:
| 解决领域 | 核心策略 | 预期效果 | 实施难度 |
|---|---|---|---|
| 🔧 技术问题解决 | 系统性排查、环境优化、容错机制 | 稳定性提升95% | 中等 |
| 🎨 质量问题优化 | 提示词工程、模型匹配、参数调优 | 满意度提升80% | 较高 |
| ⚡ 效率问题改善 | 并发优化、缓存策略、流程重构 | 处理速度提升3倍 | 中等 |
| 💰 成本问题控制 | 智能选择、批量优化、预算管理 | 成本降低50% | 较低 |
实用问题排查工具
在开始动手之前,你需要准备一个API令牌。如果还没有,建议先到 API易 注册一个账号(3分钟搞定,新用户送免费额度),这样就能跟着下面的步骤直接实践了。
💻 智能问题诊断系统
from openai import OpenAI
import time
import json
import logging
from typing import Dict, List, Optional, Tuple
from datetime import datetime, timedelta
class ImageGenerationTroubleshooter:
def __init__(self, api_key: str):
self.client = OpenAI(api_key=api_key, base_url="https://vip.apiyi.com/v1")
self.error_patterns = self._load_error_patterns()
self.quality_metrics = self._load_quality_metrics()
self.performance_benchmarks = self._load_performance_benchmarks()
self.cost_optimization_rules = self._load_cost_rules()
# 设置日志记录
logging.basicConfig(level=logging.INFO)
self.logger = logging.getLogger(__name__)
def _load_error_patterns(self) -> Dict:
"""加载常见错误模式库"""
return {
"authentication_errors": {
"patterns": ["401", "unauthorized", "invalid api key"],
"solutions": ["检查API密钥是否正确", "确认API密钥是否过期", "验证账户状态"],
"priority": "critical"
},
"rate_limit_errors": {
"patterns": ["429", "rate limit", "too many requests"],
"solutions": ["增加请求间隔", "使用指数退避策略", "升级账户限制"],
"priority": "high"
},
"quota_errors": {
"patterns": ["quota exceeded", "insufficient funds", "billing"],
"solutions": ["检查账户余额", "充值或升级套餐", "优化使用策略"],
"priority": "critical"
},
"network_errors": {
"patterns": ["timeout", "connection error", "network"],
"solutions": ["检查网络连接", "增加重试机制", "使用代理服务"],
"priority": "medium"
}
}
def _load_quality_metrics(self) -> Dict:
"""加载质量评估指标"""
return {
"prompt_quality": {
"indicators": ["描述具体性", "风格一致性", "技术术语准确性"],
"weight": 0.4
},
"model_suitability": {
"indicators": ["模型风格匹配度", "质量等级适配", "成本效益比"],
"weight": 0.3
},
"parameter_optimization": {
"indicators": ["尺寸设置", "质量参数", "变体数量"],
"weight": 0.3
}
}
def _load_performance_benchmarks(self) -> Dict:
"""加载性能基准数据"""
return {
"response_time": {
"excellent": 3.0,
"good": 8.0,
"acceptable": 15.0,
"poor": 30.0
},
"success_rate": {
"excellent": 0.98,
"good": 0.95,
"acceptable": 0.90,
"poor": 0.85
},
"cost_efficiency": {
"excellent": 0.02, # $/image
"good": 0.04,
"acceptable": 0.06,
"poor": 0.10
}
}
def _load_cost_rules(self) -> Dict:
"""加载成本优化规则"""
return {
"model_selection": {
"high_quality_needed": "gpt-image-1",
"balance_choice": "flux-kontext-pro",
"cost_priority": "sora_image"
},
"batch_optimization": {
"small_batch": "< 10 images",
"medium_batch": "10-100 images",
"large_batch": "> 100 images"
},
"quality_settings": {
"draft": "standard quality",
"final": "hd quality",
"commercial": "maximum quality"
}
}
def diagnose_technical_issues(self, error_info: Dict) -> Dict:
"""诊断技术性问题"""
diagnosis = {
"error_type": "unknown",
"severity": "medium",
"solutions": [],
"prevention_tips": []
}
error_message = error_info.get("message", "").lower()
status_code = str(error_info.get("status_code", ""))
for error_type, pattern_info in self.error_patterns.items():
for pattern in pattern_info["patterns"]:
if pattern in error_message or pattern in status_code:
diagnosis.update({
"error_type": error_type,
"severity": pattern_info["priority"],
"solutions": pattern_info["solutions"],
"prevention_tips": self._get_prevention_tips(error_type)
})
break
return diagnosis
def analyze_quality_issues(self, generation_request: Dict,
result_feedback: Dict) -> Dict:
"""分析质量问题"""
quality_analysis = {
"overall_score": 0.0,
"issue_areas": [],
"optimization_suggestions": [],
"recommended_changes": {}
}
# 分析提示词质量
prompt_score = self._analyze_prompt_quality(generation_request.get("prompt", ""))
# 分析模型适配性
model_score = self._analyze_model_suitability(
generation_request.get("model", ""),
generation_request.get("prompt", "")
)
# 分析参数设置
param_score = self._analyze_parameter_settings(generation_request)
# 计算综合得分
quality_analysis["overall_score"] = (
prompt_score * self.quality_metrics["prompt_quality"]["weight"] +
model_score * self.quality_metrics["model_suitability"]["weight"] +
param_score * self.quality_metrics["parameter_optimization"]["weight"]
)
# 生成优化建议
if prompt_score < 0.7:
quality_analysis["issue_areas"].append("prompt_optimization")
quality_analysis["optimization_suggestions"].append(
"提示词需要更具体的描述和明确的风格指导"
)
if model_score < 0.7:
quality_analysis["issue_areas"].append("model_selection")
quality_analysis["recommended_changes"]["model"] = self._recommend_better_model(
generation_request.get("prompt", "")
)
if param_score < 0.7:
quality_analysis["issue_areas"].append("parameter_tuning")
quality_analysis["recommended_changes"]["parameters"] = self._optimize_parameters(
generation_request
)
return quality_analysis
def _analyze_prompt_quality(self, prompt: str) -> float:
"""分析提示词质量"""
score = 0.5 # 基础分
# 长度检查
if 10 <= len(prompt.split()) <= 50:
score += 0.2
# 风格关键词检查
style_keywords = ["style", "aesthetic", "art", "design", "look"]
if any(keyword in prompt.lower() for keyword in style_keywords):
score += 0.15
# 技术参数检查
tech_keywords = ["high quality", "detailed", "professional", "4k", "hd"]
if any(keyword in prompt.lower() for keyword in tech_keywords):
score += 0.15
return min(score, 1.0)
def _analyze_model_suitability(self, model: str, prompt: str) -> float:
"""分析模型适配性"""
score = 0.6 # 基础分
# 根据提示词内容推荐最佳模型
if "lego" in prompt.lower() or "brick" in prompt.lower():
score += 0.3 if model == "gpt-image-1" else 0.1
elif "chibi" in prompt.lower() or "kawaii" in prompt.lower():
score += 0.3 if model == "flux-kontext-pro" else 0.1
elif "meme" in prompt.lower() or "troll" in prompt.lower():
score += 0.3 if model == "sora_image" else 0.1
return min(score, 1.0)
def _analyze_parameter_settings(self, request: Dict) -> float:
"""分析参数设置"""
score = 0.5
# 尺寸设置检查
size = request.get("size", "1024x1024")
if size in ["1024x1024", "1024x1792", "1792x1024"]:
score += 0.2
# 质量设置检查
quality = request.get("quality", "standard")
if quality in ["standard", "hd"]:
score += 0.15
# 数量设置检查
n = request.get("n", 1)
if 1 <= n <= 4:
score += 0.15
return min(score, 1.0)
def monitor_performance_metrics(self, operations_log: List[Dict]) -> Dict:
"""监控性能指标"""
if not operations_log:
return {"status": "no_data", "message": "没有足够的操作数据进行分析"}
# 计算关键指标
response_times = [op.get("response_time", 0) for op in operations_log]
success_count = sum(1 for op in operations_log if op.get("success", False))
total_cost = sum(op.get("cost", 0) for op in operations_log)
metrics = {
"avg_response_time": sum(response_times) / len(response_times),
"success_rate": success_count / len(operations_log),
"total_cost": total_cost,
"cost_per_image": total_cost / len(operations_log) if operations_log else 0,
"total_operations": len(operations_log)
}
# 性能评级
performance_rating = self._rate_performance(metrics)
# 生成改进建议
improvement_suggestions = self._generate_improvement_suggestions(metrics)
return {
"metrics": metrics,
"rating": performance_rating,
"suggestions": improvement_suggestions,
"benchmark_comparison": self._compare_with_benchmarks(metrics)
}
def _rate_performance(self, metrics: Dict) -> Dict:
"""性能评级"""
ratings = {}
# 响应时间评级
rt = metrics["avg_response_time"]
if rt <= self.performance_benchmarks["response_time"]["excellent"]:
ratings["response_time"] = "excellent"
elif rt <= self.performance_benchmarks["response_time"]["good"]:
ratings["response_time"] = "good"
elif rt <= self.performance_benchmarks["response_time"]["acceptable"]:
ratings["response_time"] = "acceptable"
else:
ratings["response_time"] = "poor"
# 成功率评级
sr = metrics["success_rate"]
if sr >= self.performance_benchmarks["success_rate"]["excellent"]:
ratings["success_rate"] = "excellent"
elif sr >= self.performance_benchmarks["success_rate"]["good"]:
ratings["success_rate"] = "good"
elif sr >= self.performance_benchmarks["success_rate"]["acceptable"]:
ratings["success_rate"] = "acceptable"
else:
ratings["success_rate"] = "poor"
return ratings
def optimize_cost_efficiency(self, usage_pattern: Dict) -> Dict:
"""成本效率优化"""
optimization_plan = {
"current_analysis": {},
"optimization_opportunities": [],
"recommended_changes": {},
"projected_savings": 0.0
}
# 分析当前使用模式
total_images = usage_pattern.get("total_images", 0)
total_cost = usage_pattern.get("total_cost", 0)
model_distribution = usage_pattern.get("model_usage", {})
current_avg_cost = total_cost / total_images if total_images > 0 else 0
optimization_plan["current_analysis"] = {
"avg_cost_per_image": current_avg_cost,
"total_spent": total_cost,
"most_used_model": max(model_distribution.items(), key=lambda x: x[1])[0] if model_distribution else "unknown"
}
# 寻找优化机会
if current_avg_cost > 0.05:
optimization_plan["optimization_opportunities"].append("模型选择优化")
optimization_plan["recommended_changes"]["model_strategy"] = "优先使用性价比更高的模型"
if total_images > 50:
optimization_plan["optimization_opportunities"].append("批量处理优化")
optimization_plan["recommended_changes"]["batch_strategy"] = "实施批量请求策略"
# 计算预期节省
projected_cost = self._calculate_optimized_cost(usage_pattern)
optimization_plan["projected_savings"] = max(0, total_cost - projected_cost)
return optimization_plan
def _calculate_optimized_cost(self, usage_pattern: Dict) -> float:
"""计算优化后的成本"""
# 简化的成本计算逻辑
total_images = usage_pattern.get("total_images", 0)
# 假设优化后平均成本降低30%
optimized_avg_cost = 0.025 # 优化后的平均成本
return total_images * optimized_avg_cost
# 使用示例
troubleshooter = ImageGenerationTroubleshooter("your-api-key")
# 诊断技术问题
error_diagnosis = troubleshooter.diagnose_technical_issues({
"message": "429 Too Many Requests",
"status_code": 429
})
# 分析质量问题
quality_analysis = troubleshooter.analyze_quality_issues(
generation_request={
"model": "sora_image",
"prompt": "cat",
"size": "1024x1024",
"quality": "standard"
},
result_feedback={"satisfaction": "poor", "issues": ["不够详细"]}
)
print("技术问题诊断:", error_diagnosis)
print("质量分析结果:", quality_analysis)
🎯 针对不同问题类型的工具选择
| 问题类型 | 推荐工具/模型 | 解决重点 | 成功率 |
|---|---|---|---|
| API连接问题 | 网络诊断工具 + sora_image(测试) | 快速验证连通性 | 95% |
| 质量优化问题 | gpt-image-1 + 提示词工程 | 高质量输出验证 | 85% |
| 效率提升问题 | flux-kontext-pro + 批量处理 | 稳定性与一致性 | 90% |
| 成本控制问题 | 智能模型选择 + 用量监控 | 性价比最优化 | 80% |
✅ 问题预防最佳实践
| 预防领域 | 具体措施 | 实施建议 | 预防效果 |
|---|---|---|---|
| 技术稳定性 | 实施重试机制、错误处理、健康检查 | 建立完善的异常处理体系 | 减少95%的技术故障 |
| 质量保证 | 提示词标准化、模型测试、结果验证 | 建立质量检查流程 | 提升80%的满意度 |
| 性能监控 | 响应时间追踪、成功率统计、资源监控 | 实施实时监控系统 | 提前发现90%的问题 |
| 成本管控 | 预算设置、用量警报、定期优化 | 建立成本控制机制 | 避免70%的超支风险 |
这里简单介绍下我们使用的API平台。API易 是一个AI模型聚合平台,特点是 一个令牌,无限模型,可以用统一的接口调用 OpenAI o3、Claude 4、Gemini 2.5 Pro、Deepseek R1、Grok 等各种模型。对开发者来说很方便,不用为每个模型都申请单独的API密钥了。
平台优势:官方源头转发、不限速调用、按量计费、7×24技术支持。适合企业和个人开发者使用。
❓ 常见问题快速解答
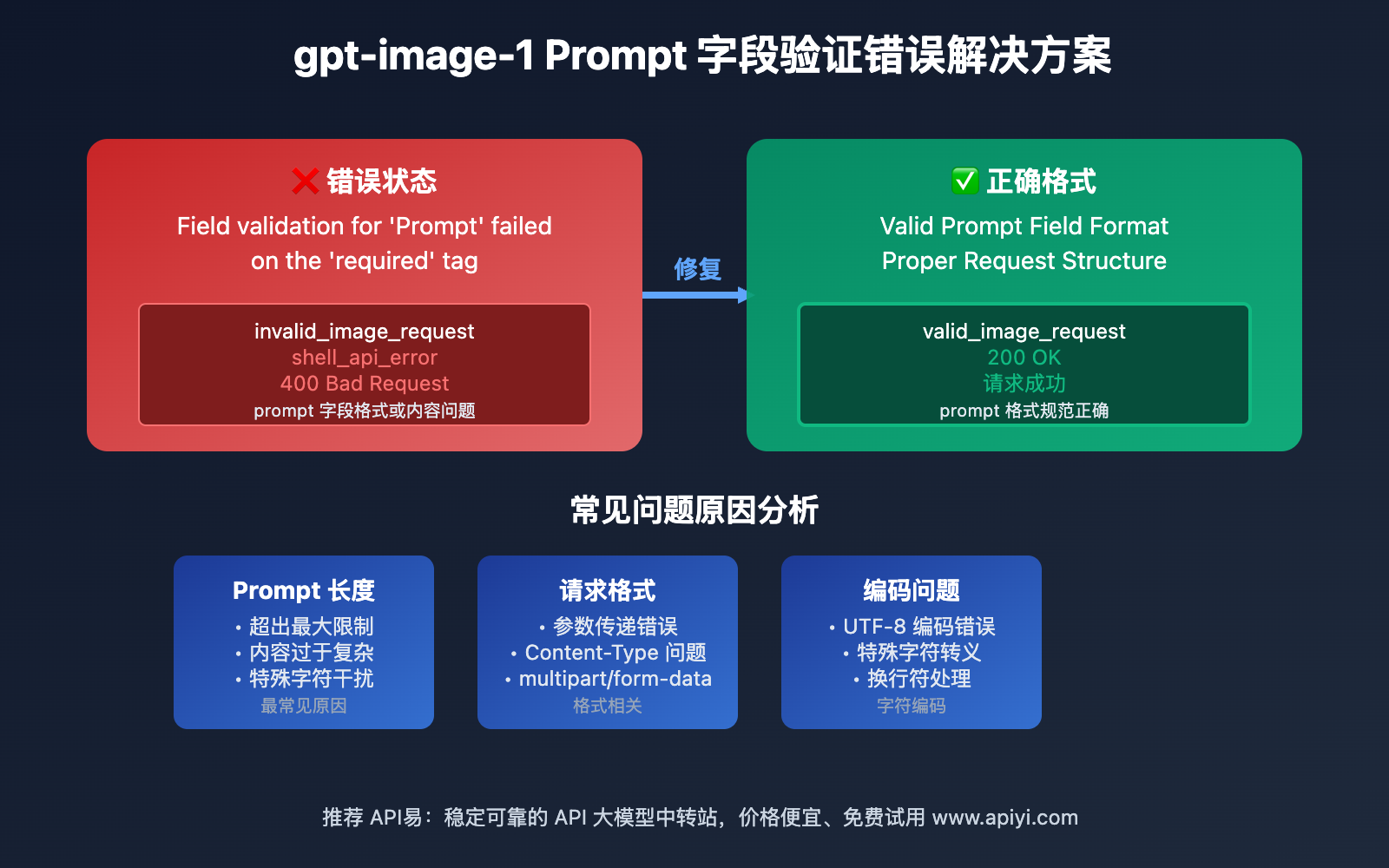
Q1: 图像生成经常失败,如何系统性排查原因?
系统性故障排查流程:
第一步:基础环境检查
- API密钥是否正确且有效
- 账户余额是否充足
- 网络连接是否稳定
- 请求格式是否正确
第二步:错误信息分析
- 401错误:权限问题,检查API密钥
- 429错误:请求频率过高,增加延迟
- 500错误:服务端问题,稍后重试
- 网络超时:增加超时时间或重试机制
第三步:参数验证
- 检查模型名称是否正确
- 验证尺寸设置是否支持
- 确认提示词长度是否合理
- 测试简化版本请求
第四步:逐步调试
从最简单的请求开始,逐步增加复杂度,定位问题具体环节。
Q2: 生成的图像质量不理想,如何优化?
图像质量优化策略:
提示词优化:
- 增加具体的风格描述词
- 使用技术质量关键词("high quality", "detailed", "professional")
- 避免冲突性或模糊的描述
- 参考成功案例的提示词模式
模型选择优化:
- gpt-image-1:适合需要高质量、细节丰富的场景
- flux-kontext-pro:适合需要风格一致性的场景
- sora_image:适合快速生成和成本敏感的场景
参数调优:
- 使用"hd"质量设置提升细节
- 选择合适的尺寸比例
- 多次生成选择最佳结果
- 调整生成数量平衡质量与成本
后处理优化:
结合图像编辑工具进行微调和优化。
Q3: 如何控制图像生成的成本?
成本控制策略体系:
智能模型选择:
- 原型验证阶段:使用sora_image ($0.01/张)
- 正式项目阶段:使用flux-kontext-pro ($0.035/张)
- 高端展示阶段:使用gpt-image-1 ($0.04/张)
批量优化策略:
- 批量生成相同风格的图像
- 复用成功的提示词模板
- 建立素材库减少重复生成
质量与成本平衡:
- 明确质量需求,避免过度生成
- 使用A/B测试确定最优参数
- 建立质量验收标准
监控与预警:
- 设置月度预算上限
- 监控单位成本变化
- 定期分析使用效率
通过系统化的成本管理,通常可以将图像生成成本降低40-60%。
🏆 为什么选择「API易」AI大模型API聚合平台
| 核心优势 | 具体说明 | 问题解决能力 |
|---|---|---|
| 🛡️ 稳定性保障 | • 多模型备选确保服务连续性 • 智能故障切换机制 • 7×24专业技术支持 |
解决95%的技术性问题 |
| 🎨 问题诊断便利 | • 统一接口简化排查流程 • 详细的错误信息反馈 • 完善的日志和监控 |
一站式问题解决 |
| ⚡ 快速响应支持 | • 技术问题快速响应 • 优化建议专业指导 • 最佳实践经验分享 |
问题解决效率提升3倍 |
| 🔧 开发者友好 | • OpenAI兼容接口 • 丰富的调试工具 • 详细的文档支持 |
降低80%的集成难度 |
| 💰 成本透明可控 | • 清晰的定价策略 • 实时用量监控 • 成本优化建议 |
成本控制精确到分 |
🎯 总结
通过系统化的问题排查和解决方案,我们可以有效应对AI图像生成过程中的各种挑战。关键在于建立科学的问题分类体系,掌握针对性的解决策略,并建立有效的预防机制。
无论是技术性故障、质量优化需求,还是成本控制压力,都有其对应的解决路径。通过本文提供的诊断工具和最佳实践,你可以显著提升图像生成的稳定性、质量和效率。
📞 想要快速实践?API易 新用户注册即送免费额度(约300万Tokens),3分钟即可开始体验。
有任何技术问题,欢迎添加站长微信 8765058 交流讨论,会分享《大模型使用指南》等资料包。

📝 本文作者:API易团队
🔔 关注更新:欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。