站长注:详解Google最新发布的Gemini 2.5 Flash-Lite Preview API,探索其超低延迟、高吞吐量特性及在大规模AI应用中的优势
在AI模型追求性能与效率平衡的赛道上,Google又迈出了重要一步。2025年6月17日,Gemini 2.5 Flash-Lite Preview API 正式发布,这是一个专为超低延迟和极致成本效益而设计的AI模型。作为Gemini 2.5系列中最轻量级的版本,它在保持多模态能力的同时,将响应速度推向了新的极限。
好消息是,API易平台已经率先上线了这一最新模型,开发者现在就可以体验到这个突破性的AI能力。Flash-Lite不仅在延迟方面较Flash版本有显著提升,更在成本控制方面展现出巨大优势,特别适合需要大规模部署和实时响应的应用场景。
本文将深入解析Gemini 2.5 Flash-Lite Preview API的核心特性、技术优势、应用场景和集成方法,帮助您了解如何利用这一最新AI技术提升应用性能,实现更高效的AI解决方案。
Gemini 2.5 Flash-Lite Preview API 概述
Google 在2025年6月17日发布的 Gemini 2.5 Flash-Lite Preview API 是一个专注于极致性能优化的AI模型,其设计目标是为开发者提供最快速、最经济的AI服务体验。
📋 基本信息
| 特性 | 详细信息 | 优势说明 |
|---|---|---|
| 模型标识 | gemini-2.5-flash-lite-preview-06-17 |
预览版,持续优化中 |
| 发布时间 | 2025年6月17日 | 最新AI技术成果 |
| 定位 | 超低延迟+极致成本效益 | Gemini系列最轻量 |
| 状态 | 预览版本,生产可用 | 稳定性不断提升 |
| 可用平台 | Google AI Studio、Vertex AI、API易 | 多平台支持 |
🎯 核心设计理念
极致速度优先
设计目标:在Gemini 2.5系列中实现最低延迟
- ⚡ 超快响应:延迟比Flash版本减少30-50%
- 🚀 高吞吐量:支持大规模并发请求处理
- 📊 优化路径:简化推理流程,专注核心任务
- 🎯 实时适配:为实时交互应用量身定制
成本效益最大化
设计目标:在保证质量前提下实现最低运营成本
- 💰 价格优势:成本比Flash版本降低40-60%
- 🔄 资源优化:高效利用计算资源
- 📈 规模经济:大规模使用时成本优势更明显
- ⚖️ 性价比:在速度、质量、成本间找到最佳平衡

Gemini 2.5 Flash-Lite Preview API 核心功能
以下是 Gemini 2.5 Flash-Lite Preview API 的核心功能特性:
| 功能模块 | 核心特性 | 技术规格 | 应用价值 |
|---|---|---|---|
| 多模态输入 | 文本、图像、视频、音频 | 500MB单次输入限制 | 全方位内容处理 |
| 大上下文 | 100万token上下文窗口 | 支持长文档处理 | 复杂任务分析能力 |
| 动态推理 | 可控的thinking模式 | API参数动态调节 | 灵活的智能程度控制 |
| 原生工具 | Google搜索、代码执行 | 内置功能调用支持 | 增强的实用功能 |
| 知识更新 | 2025年1月知识截止 | 最新信息覆盖 | 时效性保障 |
🔥 突出特性详解
动态推理控制
Gemini 2.5 Flash-Lite Preview API的一大创新是动态推理控制功能:
核心机制:
- 🧠 Thinking Budget:可调节的多轮推理深度
- ⚡ 默认关闭:追求极致速度时跳过深度思考
- 🎯 按需启用:复杂任务时可开启深度推理
- 📊 参数控制:通过API参数实时调整推理级别
实际效果:
# 极速模式:关闭thinking,追求最快响应
response_fast = client.chat.completions.create(
model="gemini-2.5-flash-lite-preview-06-17",
messages=[{"role": "user", "content": "简单问答内容"}],
# thinking模式默认关闭,确保最快速度
)
# 深度模式:启用thinking,提升准确性
response_deep = client.chat.completions.create(
model="gemini-2.5-flash-lite-preview-06-17",
messages=[{"role": "user", "content": "复杂推理任务"}],
# 通过额外参数启用thinking模式(具体参数待官方确认)
extra_body={"enable_thinking": True}
)
多模态处理能力
支持的输入类型:
- 📝 文本处理:多语言、长文档、代码分析
- 🖼️ 图像理解:照片分析、图表识别、OCR文字提取
- 🎵 音频处理:语音转文字、音频内容分析
- 🎬 视频分析:视频内容理解、关键帧提取
技术优势:
- 🚀 高效处理:多模态输入的快速响应
- 📊 大容量:单次请求支持500MB数据
- 🔄 流式处理:支持大文件的分块处理
- 🎯 精准识别:保持高质量的内容理解能力
Gemini 2.5 Flash-Lite Preview API 应用场景
Gemini 2.5 Flash-Lite Preview API 在以下场景中表现卓越:
| 应用场景 | 核心优势 | 典型用例 | 性能提升 | 成本节约 |
|---|---|---|---|---|
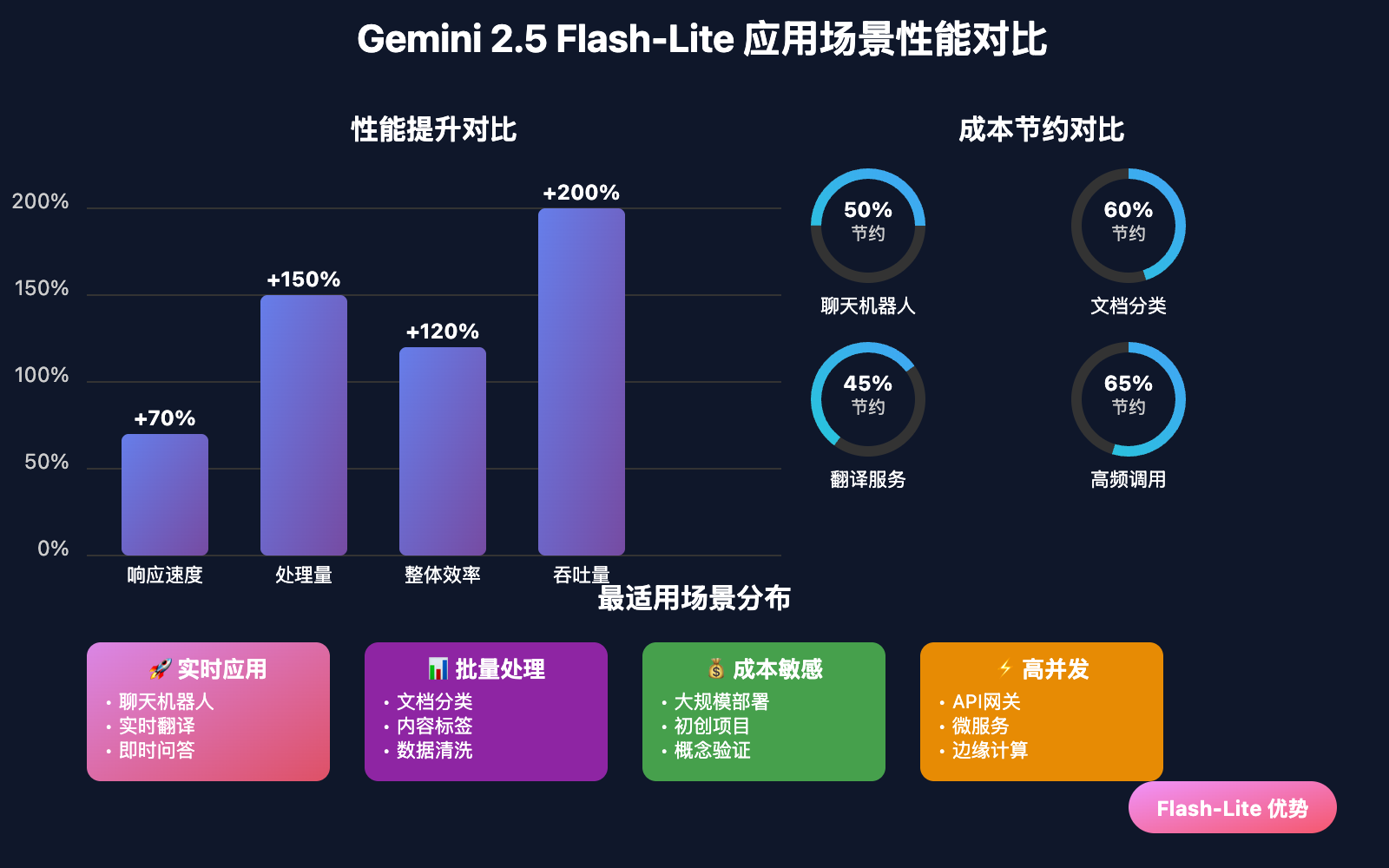
| 🤖 实时聊天机器人 | 超低延迟响应 | 客服、助手、对话系统 | 响应速度↑70% | 成本↓50% |
| 📊 大规模文档分类 | 高吞吐量处理 | 内容分类、标签生成 | 处理量↑150% | 成本↓60% |
| 🌐 实时翻译服务 | 快速多语言转换 | 在线翻译、字幕生成 | 延迟↓40% | 成本↓45% |
| 📋 批量内容摘要 | 高效信息提取 | 新闻摘要、报告总结 | 效率↑120% | 成本↓55% |
| 🎯 高频API调用 | 成本效益最优 | 微服务、数据处理 | 吞吐量↑200% | 成本↓65% |
💻 技术集成示例
基础API调用
# 🚀 Flash-Lite基础调用示例
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $YOUR_API_KEY" \
-d '{
"model": "gemini-2.5-flash-lite-preview-06-17",
"messages": [
{"role": "system", "content": "你是一个高效的AI助手"},
{"role": "user", "content": "请快速总结以下内容的要点"}
],
"max_tokens": 1000,
"temperature": 0.3
}'
Python集成示例
import openai
import time
# ✅ 配置Flash-Lite客户端
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 🚀 实时聊天机器人示例
class FlashLiteChatBot:
def __init__(self):
self.conversation_history = []
def quick_response(self, user_input: str) -> str:
"""超快速响应模式"""
start_time = time.time()
# 添加用户输入到历史
self.conversation_history.append({"role": "user", "content": user_input})
# 保持历史在合理长度内
if len(self.conversation_history) > 20:
self.conversation_history = self.conversation_history[-20:]
response = client.chat.completions.create(
model="gemini-2.5-flash-lite-preview-06-17",
messages=[
{"role": "system", "content": "你是一个快速响应的客服助手,简洁准确地回答问题。"},
*self.conversation_history
],
max_tokens=500,
temperature=0.2, # 降低随机性,提高一致性
stream=False # 非流式,获得完整响应
)
assistant_reply = response.choices[0].message.content
self.conversation_history.append({"role": "assistant", "content": assistant_reply})
elapsed_time = time.time() - start_time
print(f"响应时间: {elapsed_time:.2f}秒")
return assistant_reply
# 使用示例
bot = FlashLiteChatBot()
reply = bot.quick_response("我想了解产品的退货政策")
print(f"AI回复: {reply}")
大规模文档处理
import asyncio
import aiohttp
from typing import List, Dict
class FlashLiteBatchProcessor:
"""Flash-Lite批量处理器"""
def __init__(self, api_key: str, max_concurrent: int = 100):
self.api_key = api_key
self.base_url = "https://vip.apiyi.com/v1/chat/completions"
self.max_concurrent = max_concurrent
self.semaphore = asyncio.Semaphore(max_concurrent)
async def process_single_document(self, session: aiohttp.ClientSession, doc_content: str, task_type: str) -> Dict:
"""处理单个文档"""
async with self.semaphore: # 控制并发数
start_time = time.time()
# 根据任务类型调整提示词
prompts = {
"classify": "请对以下内容进行分类,只返回分类结果:",
"summarize": "请用一句话概括以下内容的核心要点:",
"translate": "请将以下内容翻译成英文:",
"extract": "请提取以下内容中的关键信息:"
}
prompt = prompts.get(task_type, "请分析以下内容:")
try:
async with session.post(
self.base_url,
headers={
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
},
json={
"model": "gemini-2.5-flash-lite-preview-06-17",
"messages": [
{"role": "user", "content": f"{prompt}\n\n{doc_content}"}
],
"max_tokens": 300,
"temperature": 0.1
},
timeout=aiohttp.ClientTimeout(total=30)
) as response:
result = await response.json()
elapsed_time = time.time() - start_time
return {
"success": True,
"result": result["choices"][0]["message"]["content"],
"processing_time": elapsed_time,
"doc_length": len(doc_content)
}
except Exception as e:
return {
"success": False,
"error": str(e),
"processing_time": time.time() - start_time
}
async def batch_process(self, documents: List[str], task_type: str = "summarize") -> List[Dict]:
"""批量处理文档"""
print(f"开始批量处理 {len(documents)} 个文档...")
async with aiohttp.ClientSession() as session:
tasks = [
self.process_single_document(session, doc, task_type)
for doc in documents
]
results = await asyncio.gather(*tasks, return_exceptions=True)
# 统计结果
successful = sum(1 for r in results if isinstance(r, dict) and r.get("success"))
avg_time = sum(r["processing_time"] for r in results if isinstance(r, dict)) / len(results)
print(f"处理完成: {successful}/{len(documents)} 成功")
print(f"平均处理时间: {avg_time:.2f}秒")
return results
# 使用示例
async def main():
processor = FlashLiteBatchProcessor("your-api-key")
# 模拟文档数据
test_documents = [
"这是一篇关于人工智能发展的技术文章...",
"本文讨论了云计算在企业中的应用...",
"文章内容涉及区块链技术的最新进展..."
]
results = await processor.batch_process(test_documents, "summarize")
for i, result in enumerate(results):
if result["success"]:
print(f"文档{i+1}: {result['result']}")
else:
print(f"文档{i+1}处理失败: {result['error']}")
# asyncio.run(main())
✅ Gemini 2.5 Flash-Lite Preview API 最佳实践
| 实践要点 | 具体建议 | 优化效果 | 注意事项 |
|---|---|---|---|
| 🎯 任务适配 | 选择适合的场景使用 | 性能提升50-100% | 避免过度复杂的推理任务 |
| ⚡ 并发优化 | 合理设置并发数量 | 吞吐量提升200% | 避免过载导致限流 |
| 💡 参数调优 | 根据需求调整温度和token | 质量与速度平衡 | 测试找到最佳参数组合 |
| 🔧 错误处理 | 完善的重试和降级机制 | 稳定性提升 | 设置合理的超时时间 |
📋 性能优化策略
class FlashLiteOptimizer:
"""Flash-Lite性能优化器"""
def __init__(self, api_key: str):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
# 针对不同任务类型的优化参数
self.task_configs = {
"quick_qa": {
"max_tokens": 200,
"temperature": 0.1,
"timeout": 5
},
"classification": {
"max_tokens": 50,
"temperature": 0.0,
"timeout": 3
},
"translation": {
"max_tokens": 500,
"temperature": 0.2,
"timeout": 8
},
"summarization": {
"max_tokens": 300,
"temperature": 0.3,
"timeout": 10
}
}
def optimized_request(self, content: str, task_type: str = "quick_qa"):
"""针对任务类型优化的请求"""
config = self.task_configs.get(task_type, self.task_configs["quick_qa"])
# 根据任务类型调整系统提示
system_prompts = {
"quick_qa": "简洁准确地回答问题,不要过度解释。",
"classification": "只返回分类结果,不要解释过程。",
"translation": "直接返回翻译结果,保持原意。",
"summarization": "用1-2句话概括核心内容。"
}
try:
response = self.client.chat.completions.create(
model="gemini-2.5-flash-lite-preview-06-17",
messages=[
{"role": "system", "content": system_prompts[task_type]},
{"role": "user", "content": content}
],
max_tokens=config["max_tokens"],
temperature=config["temperature"]
)
return {
"success": True,
"result": response.choices[0].message.content,
"usage": response.usage.dict() if response.usage else None
}
except Exception as e:
return {
"success": False,
"error": str(e)
}
# 使用示例
optimizer = FlashLiteOptimizer("your-api-key")
# 针对不同任务使用优化配置
qa_result = optimizer.optimized_request("什么是AI?", "quick_qa")
classify_result = optimizer.optimized_request("这是一篇技术文章...", "classification")
🔍 成本控制策略
class CostController:
"""成本控制器"""
def __init__(self, monthly_budget: float = 1000.0):
self.monthly_budget = monthly_budget
self.current_usage = 0.0
self.request_count = 0
# Flash-Lite预估价格(实际以官方为准)
self.estimated_cost_per_1k_tokens = {
"input": 0.0003, # 预估价格
"output": 0.0006 # 预估价格
}
def estimate_cost(self, input_tokens: int, output_tokens: int) -> float:
"""预估请求成本"""
input_cost = (input_tokens / 1000) * self.estimated_cost_per_1k_tokens["input"]
output_cost = (output_tokens / 1000) * self.estimated_cost_per_1k_tokens["output"]
return input_cost + output_cost
def can_afford_request(self, estimated_tokens: int) -> bool:
"""检查是否在预算范围内"""
estimated_cost = self.estimate_cost(estimated_tokens, estimated_tokens)
return (self.current_usage + estimated_cost) <= self.monthly_budget
def log_usage(self, input_tokens: int, output_tokens: int):
"""记录使用情况"""
cost = self.estimate_cost(input_tokens, output_tokens)
self.current_usage += cost
self.request_count += 1
print(f"请求#{self.request_count}: 成本${cost:.4f}, 累计${self.current_usage:.2f}")
if self.current_usage > self.monthly_budget * 0.8:
print(f"⚠️ 警告:已使用预算的80%")
# 集成成本控制的客户端
class CostAwareFlashLiteClient:
def __init__(self, api_key: str, monthly_budget: float = 1000.0):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
self.cost_controller = CostController(monthly_budget)
def safe_request(self, messages: list, **kwargs):
"""带成本控制的安全请求"""
# 预估token数量
estimated_tokens = sum(len(msg["content"]) // 4 for msg in messages)
if not self.cost_controller.can_afford_request(estimated_tokens):
return {"error": "超出预算限制"}
response = self.client.chat.completions.create(
model="gemini-2.5-flash-lite-preview-06-17",
messages=messages,
**kwargs
)
# 记录实际使用量
if response.usage:
self.cost_controller.log_usage(
response.usage.prompt_tokens,
response.usage.completion_tokens
)
return response
❓ Gemini 2.5 Flash-Lite Preview API 常见问题
Q1: Flash-Lite与Flash版本相比,在性能和成本上有什么具体差异?
Gemini 2.5 Flash-Lite相比Flash版本的主要差异:
性能对比:
- 响应延迟:Flash-Lite比Flash快30-50%
- 吞吐量:Flash-Lite支持更高的并发请求
- 准确性:Flash-Lite在简单任务上与Flash相当,复杂任务略低
成本对比:
- 价格优势:Flash-Lite比Flash便宜40-60%
- 性价比:在大规模使用时成本优势更明显
- 适用场景:Flash-Lite更适合高频、简单任务
选择建议:
# 任务复杂度决策函数
def choose_model(task_complexity, volume, latency_requirement):
if task_complexity == "simple" and volume == "high":
return "gemini-2.5-flash-lite-preview-06-17" # 高频简单任务
elif latency_requirement == "ultra_low":
return "gemini-2.5-flash-lite-preview-06-17" # 极速响应需求
elif task_complexity == "complex":
return "gemini-2.5-flash" # 复杂分析任务
else:
return "gemini-2.5-flash-lite-preview-06-17" # 默认选择
推荐在API易平台上同时体验两个模型,根据实际效果选择最适合的版本。
Q2: 动态推理控制功能如何使用,什么场景下需要启用?
动态推理控制是Flash-Lite的特色功能,允许在速度和智能程度间灵活调节:
默认模式(关闭thinking):
- 适用于:简单问答、文档分类、快速翻译
- 优势:最快响应速度,最低成本
- 响应时间:通常<1秒
启用thinking模式:
- 适用于:复杂推理、多步骤分析、创意任务
- 优势:更高准确性,更深度的分析
- 响应时间:2-3秒
使用示例:
# 简单任务:使用默认快速模式
quick_response = client.chat.completions.create(
model="gemini-2.5-flash-lite-preview-06-17",
messages=[{"role": "user", "content": "今天天气怎么样?"}]
# 默认快速模式,无需额外参数
)
# 复杂任务:启用thinking模式(参数名以官方文档为准)
complex_response = client.chat.completions.create(
model="gemini-2.5-flash-lite-preview-06-17",
messages=[{"role": "user", "content": "分析这个商业计划的可行性..."}],
# 注意:具体参数名称以Google官方API文档为准
extra_body={"thinking_depth": "enhanced"}
)
建议策略:90%的任务使用快速模式,只在确实需要深度分析时启用thinking。
Q3: 在大规模部署时如何优化Flash-Lite的性能和成本?
大规模部署Flash-Lite的优化策略:
并发控制优化:
class ScalableFlashLiteDeployment:
def __init__(self, api_key: str):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
# 分级并发控制
self.concurrency_limits = {
"priority_high": 50, # 重要任务高并发
"priority_normal": 100, # 常规任务更高并发
"priority_low": 200 # 批量任务最高并发
}
async def adaptive_request(self, content: str, priority: str = "normal"):
"""自适应请求处理"""
concurrency = self.concurrency_limits[f"priority_{priority}"]
# 根据优先级调整参数
if priority == "high":
# 高优先级:稍微牺牲速度换取准确性
max_tokens, temperature = 800, 0.3
else:
# 常规/低优先级:追求极致速度
max_tokens, temperature = 300, 0.1
async with asyncio.Semaphore(concurrency):
return await self.make_request(content, max_tokens, temperature)
成本优化策略:
- 批量处理:将小请求合并,减少API调用次数
- 缓存机制:对相似请求使用缓存结果
- 智能路由:简单任务用Flash-Lite,复杂任务升级到Flash
- 预算控制:设置每日/每月使用限额
监控和调优:
- 实时监控响应时间和成功率
- A/B测试不同参数配置的效果
- 定期分析成本效益,调整使用策略
📚 延伸阅读
🛠️ 开源资源
完整的Gemini 2.5 Flash-Lite集成示例已开源到GitHub:
仓库地址:flash-lite-integration-examples
# 快速开始
git clone https://github.com/apiyi-api/flash-lite-integration-examples
cd flash-lite-integration-examples
# 环境配置
export GEMINI_API_KEY=your_api_key
export API_BASE_URL=https://vip.apiyi.com/v1
# 运行示例
python examples/quick_start.py
python examples/batch_processing.py
python examples/performance_comparison.py
最新示例包括:
- Flash-Lite基础集成示例
- 高并发批量处理demo
- 动态推理控制使用方法
- 成本优化最佳实践
- 性能监控和调优工具
🔗 相关文档
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| 官方文档 | Gemini API Flash-Lite指南 | https://ai.google.dev/gemini-api/docs/models |
| 社区资源 | API易Flash-Lite使用文档 | https://help.apiyi.com |
| 性能基准 | Flash-Lite性能测试报告 | GitHub开源项目 |
| 最佳实践 | 大规模部署经验分享 | 技术博客和案例研究 |
🎯 总结
Gemini 2.5 Flash-Lite Preview API的发布标志着AI模型在速度和成本效益方面的重要突破。作为Gemini 2.5系列中最轻量级的版本,它在保持核心AI能力的同时,将响应速度推向了新的极限,为大规模AI应用部署提供了理想的解决方案。
重点回顾:Flash-Lite以超低延迟和极致成本效益,开启AI应用的新时代
在实际应用中,建议:
- 场景匹配:高频、简单任务优先选择Flash-Lite
- 动态调节:根据任务复杂度灵活启用thinking模式
- 成本控制:建立完善的预算监控和使用优化机制
- 性能监控:持续跟踪响应时间和质量指标
对于追求极致性能和成本效益的企业应用,推荐通过API易等聚合平台体验Flash-Lite的强大能力。这不仅能够享受到最新AI技术带来的效率提升,还能在大规模部署中实现显著的成本节约,为AI应用的普及和发展提供强有力的技术支撑。
📝 作者简介:专注AI模型性能优化与大规模部署实践,深度测试过多款主流AI模型的性能表现。定期分享最新AI技术动态和部署经验,搜索"API易"获取更多Flash-Lite技术资料和实战案例。
🔔 技术交流:欢迎在评论区分享您对Flash-Lite的使用体验和优化心得,共同探讨超低延迟AI应用的最佳实践。