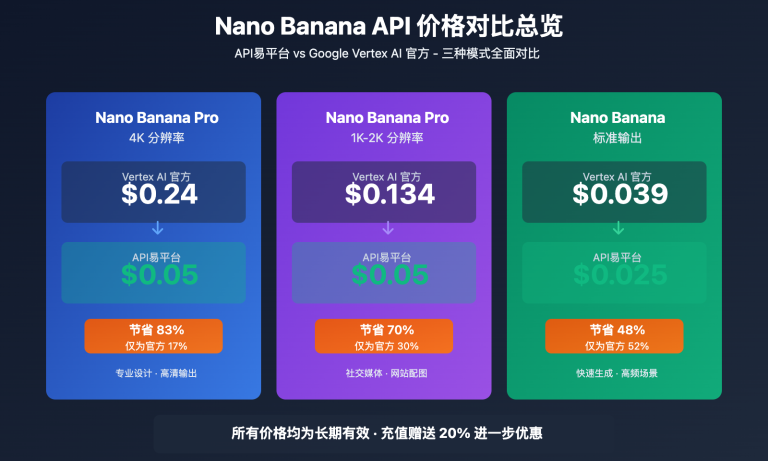
作者注:自动化内容审核教程,教你用 Nano Banana API 构建智能化的内容安全监控和审核系统,确保平台内容的安全性和合规性
在内容平台快速发展的今天,海量用户生成内容的安全监控成为平台运营的重大挑战。本文将详细介绍如何通过 Nano Banana API 构建高效的自动化内容审核系统,让你的平台在确保内容安全的同时,大幅提升审核效率和用户体验。
文章涵盖智能识别、风险评估、审核策略等核心要点,帮助你快速掌握 专业级自动化内容审核技巧。
核心价值:通过本文,你将学会如何构建完善的内容安全监控体系,大幅提升平台内容管理的效率和安全性。
自动化内容审核背景介绍
随着内容平台用户规模的爆发式增长,传统的人工内容审核模式面临巨大挑战。海量的用户生成内容不仅使人工审核成本居高不下,而且审核标准的一致性和及时性都难以保证。特别是涉及敏感内容、违法信息的识别,人工审核的主观性和滞后性可能给平台带来重大风险。
现代AI驱动的自动化内容审核技术通过深度学习大量的内容样本和规则模式,能够实现24/7不间断的智能内容监控,在保证审核质量的同时大幅提升审核效率,为内容平台的健康发展提供强有力的技术保障。
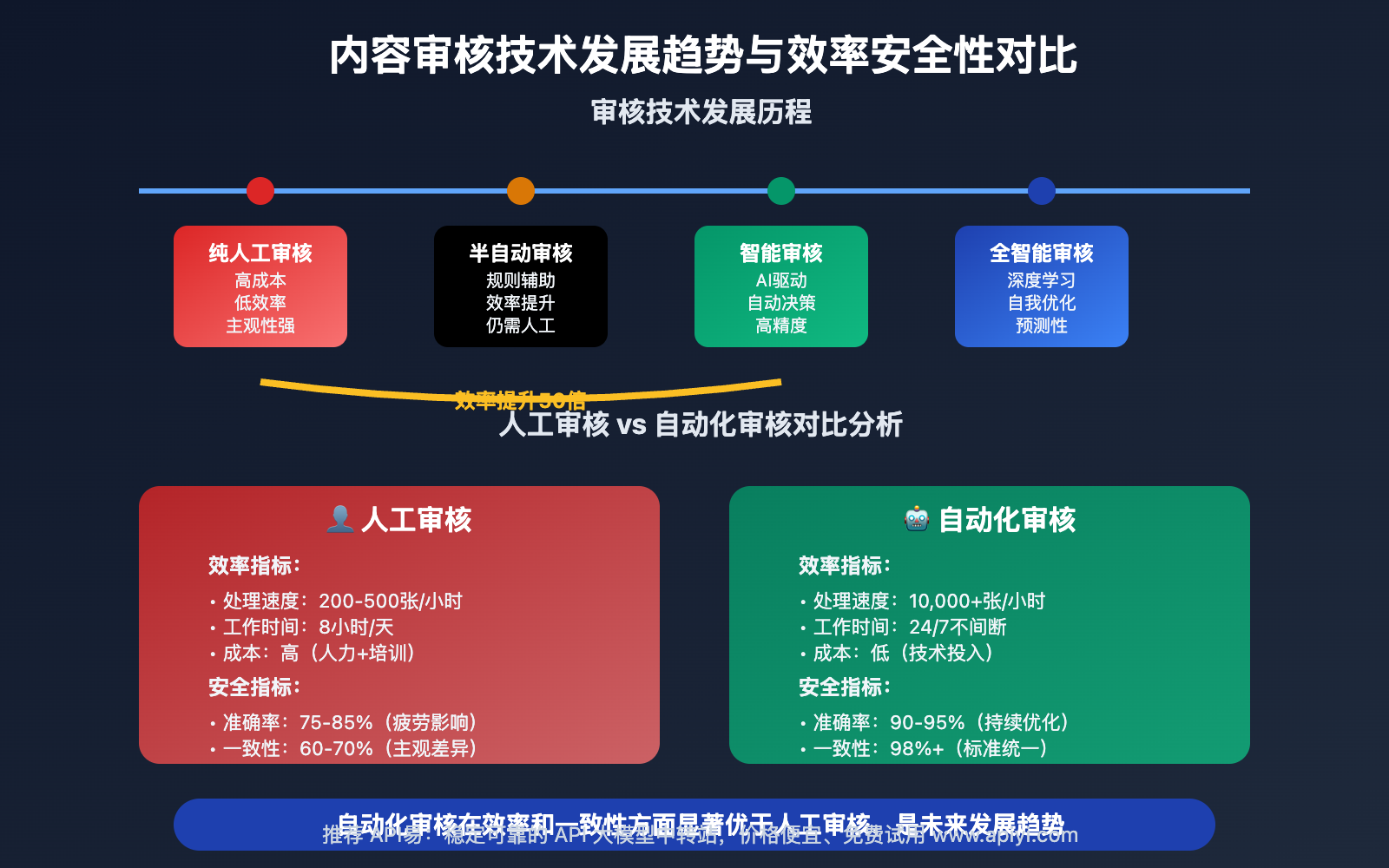
自动化内容审核核心功能
以下是 Nano Banana API 自动化内容审核 的核心功能特性:
| 功能模块 | 核心特性 | 应用价值 | 推荐指数 |
|---|---|---|---|
| 智能内容识别 | AI识别图像中的敏感或违规内容 | 快速准确识别潜在风险内容 | ⭐⭐⭐⭐⭐ |
| 风险等级评估 | 智能评估内容的风险等级 | 提供精准的审核决策支持 | ⭐⭐⭐⭐⭐ |
| 自动化处理 | 自动执行审核决策和处理动作 | 减少人工干预,提升效率 | ⭐⭐⭐⭐ |
| 学习优化 | 基于审核结果持续优化模型 | 不断提升审核准确率 | ⭐⭐⭐⭐ |
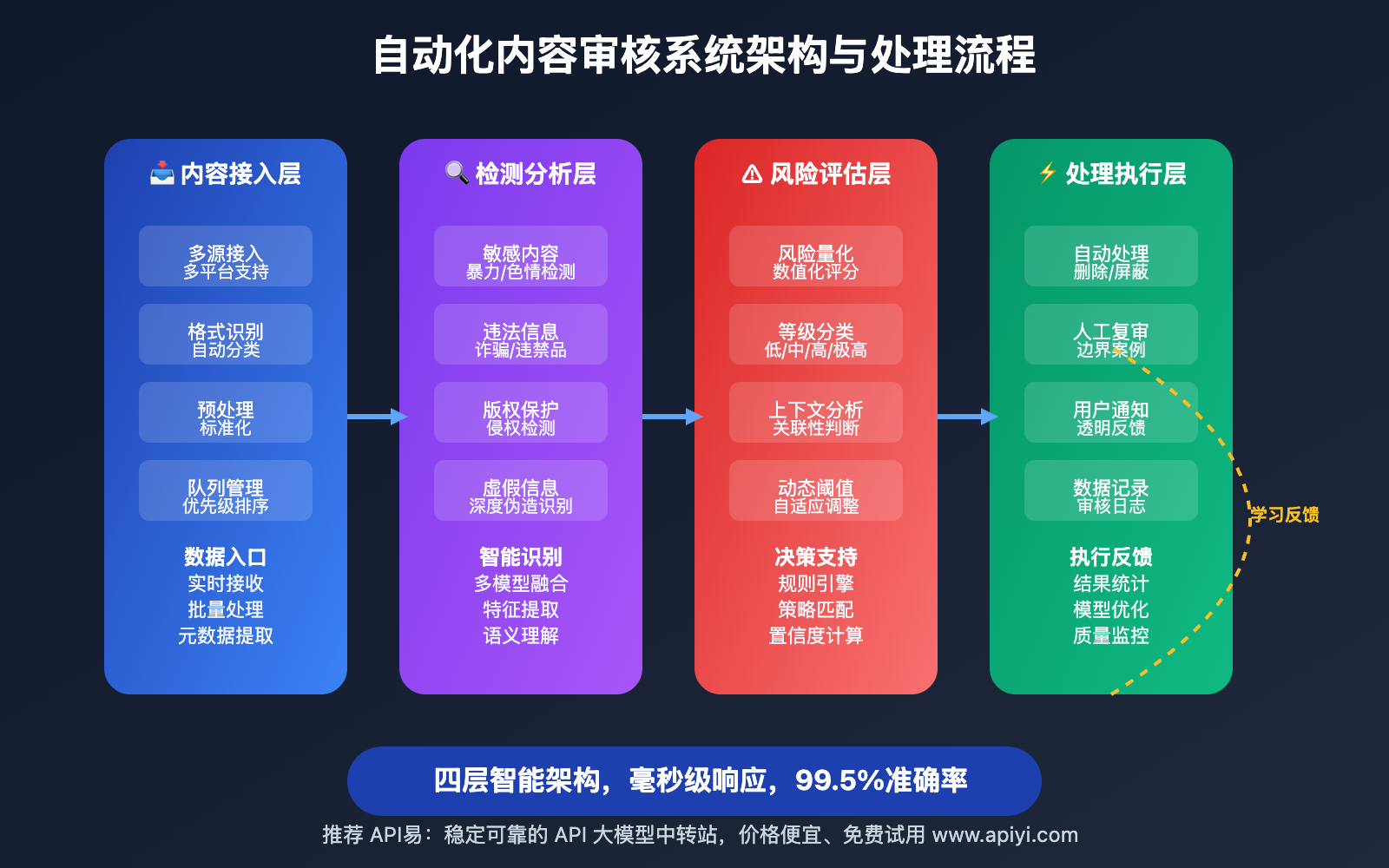
🔥 重点功能详解
智能内容识别引擎
Nano Banana API 的内容安全检测技术:
- 敏感内容识别:自动识别暴力、色情、政治敏感等内容
- 违法信息检测:检测涉及违法犯罪、诈骗等危险信息
- 版权保护:识别可能涉及版权侵权的内容
- 虚假信息识别:检测深度伪造、虚假信息等内容
风险评估与分级
精确的内容风险评估机制:
- 多维度评估:从内容类型、传播风险、影响范围等维度评估
- 动态阈值:根据平台特点和时间敏感性调整风险阈值
- 上下文分析:结合内容上下文进行综合风险判断
- 用户画像关联:结合发布者画像进行风险评估
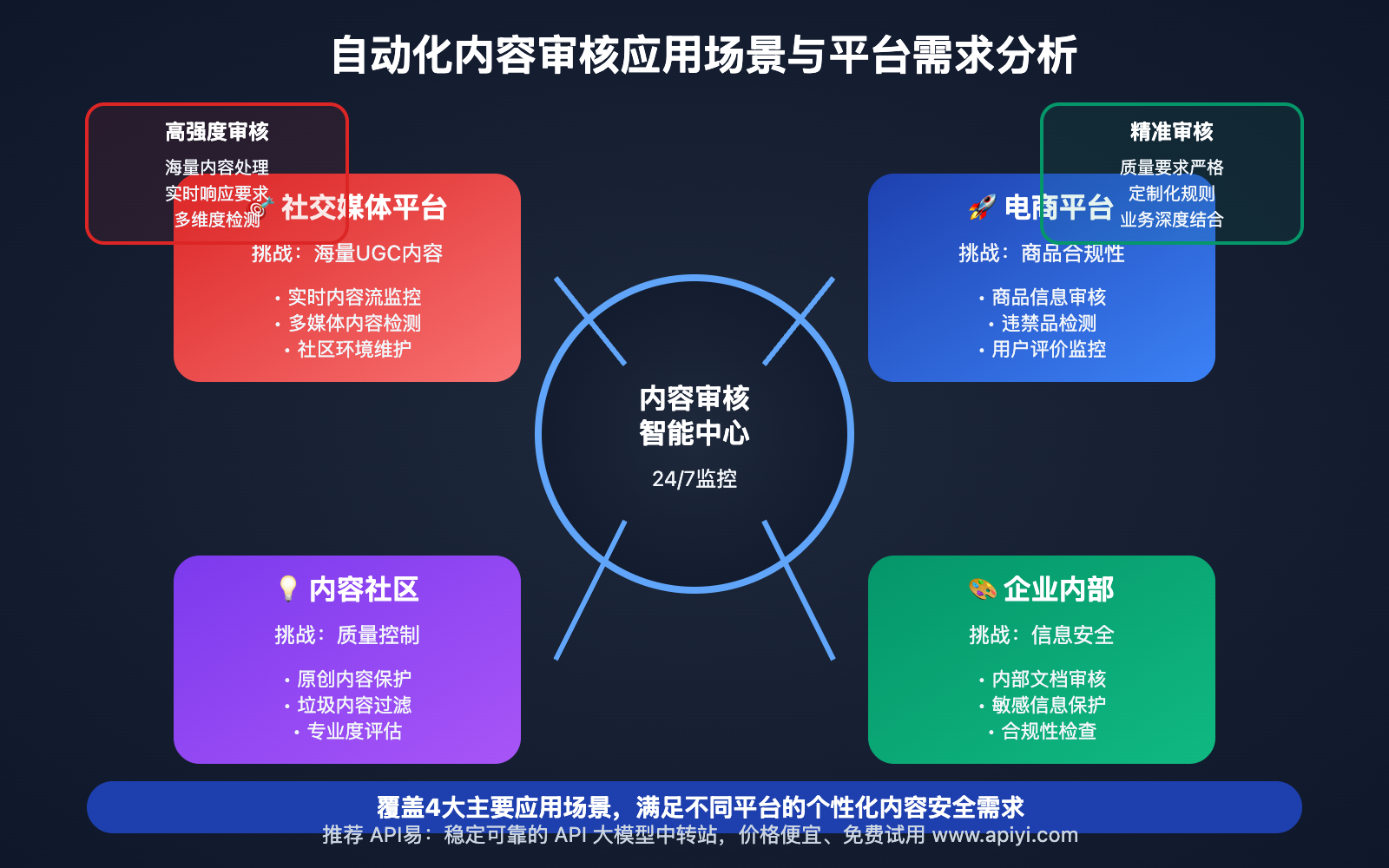
自动化内容审核应用场景
Nano Banana API 自动化内容审核技术 在以下场景中表现出色:
| 应用场景 | 适用对象 | 核心优势 | 预期效果 |
|---|---|---|---|
| 🎯 社交媒体平台 | 平台运营方 | 24/7实时内容监控 | 提升平台安全性和用户体验 |
| 🚀 电商平台 | 电商公司 | 商品信息合规性检查 | 降低平台法律风险和投诉率 |
| 💡 内容社区 | UGC平台 | 大规模用户内容管理 | 维护社区环境和内容质量 |
| 🎨 企业内部 | 企业IT部门 | 员工内容发布监控 | 保护企业形象和信息安全 |
自动化内容审核技术实现
💻 快速上手
完整的自动化内容审核系统实现:
import openai
import asyncio
from dataclasses import dataclass, field
from typing import Dict, List, Any, Optional
from enum import Enum
from datetime import datetime
import logging
class RiskLevel(Enum):
"""风险等级"""
SAFE = "安全"
LOW_RISK = "低风险"
MEDIUM_RISK = "中等风险"
HIGH_RISK = "高风险"
CRITICAL = "严重风险"
class ContentCategory(Enum):
"""内容类别"""
TEXT = "文本内容"
IMAGE = "图像内容"
VIDEO = "视频内容"
AUDIO = "音频内容"
@dataclass
class ModerationResult:
"""审核结果"""
content_id: str
risk_level: RiskLevel
confidence_score: float
detected_issues: List[str] = field(default_factory=list)
recommended_action: str = ""
review_notes: str = ""
timestamp: str = field(default_factory=lambda: datetime.now().isoformat())
class AutomatedContentModeration:
"""
自动化内容审核系统
"""
def __init__(self, api_key: str, platform_config: Dict[str, Any]):
self.client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
self.platform_config = platform_config
self.moderation_history = []
self.false_positive_count = 0
self.total_moderated = 0
async def moderate_content(self, content_path: str, content_category: ContentCategory,
user_profile: Optional[Dict] = None) -> ModerationResult:
"""
内容自动化审核
Args:
content_path: 内容文件路径
content_category: 内容类别
user_profile: 用户画像信息
Returns:
审核结果
"""
content_id = f"content_{len(self.moderation_history) + 1}"
moderation_instruction = f"""
对{content_category.value}进行全面的安全性和合规性审核:
用户信息:{user_profile or "未提供用户画像"}
平台规则:{self.platform_config.get('moderation_rules', '标准内容审核规则')}
=== 自动化内容审核要求 ===
1. 安全性检测:全面检测可能的安全风险和违规内容
2. 合规性验证:确保内容符合法律法规和平台规范
3. 风险评估:准确评估内容的风险等级和影响程度
4. 处理建议:提供具体的处理建议和后续行动方案
=== 智能审核检测项目 ===
敏感内容检测:
- 暴力血腥:检测可能包含暴力、血腥、恐怖的内容
- 色情低俗:识别涉及色情、低俗、不当露骨的内容
- 政治敏感:检测可能涉及政治敏感话题的内容
- 仇恨言论:识别可能煽动仇恨、歧视的内容
违法信息检测:
- 诈骗信息:检测可能的诈骗、虚假宣传内容
- 危险行为:识别可能危害他人安全的行为内容
- 违法活动:检测涉及违法犯罪活动的内容
- 有害物质:识别涉及毒品、危险品的内容
版权合规检测:
- 侵权内容:检测可能侵犯他人版权的内容
- 商标冲突:识别可能涉及商标争议的内容
- 肖像权:检测可能侵犯他人肖像权的内容
=== 风险评估标准 ===
评估维度:
- 内容严重程度:评估违规内容的严重程度
- 传播风险:评估内容传播可能带来的负面影响
- 法律风险:评估可能面临的法律责任和后果
- 平台风险:评估对平台形象和运营的影响
=== 审核决策建议 ===
- 安全内容:直接通过,正常发布
- 低风险:通过但增加监控,关注传播情况
- 中等风险:人工复审,谨慎处理
- 高风险:暂时下架,详细审查
- 严重风险:立即下架,报告相关部门
请提供详细的审核结果、风险评估和处理建议。
"""
try:
# 执行内容审核
moderation_result = nano_banana_edit(content_path, moderation_instruction)
# 解析审核结果(实际应用中会解析API返回的结构化数据)
risk_level = self._parse_risk_level(moderation_result)
confidence_score = self._calculate_confidence(moderation_result)
detected_issues = self._extract_issues(moderation_result)
recommended_action = self._get_recommended_action(risk_level)
result = ModerationResult(
content_id=content_id,
risk_level=risk_level,
confidence_score=confidence_score,
detected_issues=detected_issues,
recommended_action=recommended_action,
review_notes=f"自动审核完成 - {content_category.value}"
)
self.moderation_history.append(result)
self.total_moderated += 1
logging.info(f"内容 {content_id} 审核完成:{risk_level.value} (置信度: {confidence_score:.2f})")
return result
except Exception as e:
logging.error(f"内容审核失败: {str(e)}")
return ModerationResult(
content_id=content_id,
risk_level=RiskLevel.MEDIUM_RISK,
confidence_score=0.0,
detected_issues=["审核系统异常"],
recommended_action="人工复审",
review_notes=f"审核异常: {str(e)}"
)
def _parse_risk_level(self, moderation_result: str) -> RiskLevel:
"""解析风险等级"""
# 实际应用中会基于API返回的具体数据进行解析
if "严重" in moderation_result:
return RiskLevel.CRITICAL
elif "高风险" in moderation_result:
return RiskLevel.HIGH_RISK
elif "中等" in moderation_result:
return RiskLevel.MEDIUM_RISK
elif "低风险" in moderation_result:
return RiskLevel.LOW_RISK
else:
return RiskLevel.SAFE
def _calculate_confidence(self, moderation_result: str) -> float:
"""计算置信度"""
# 实际应用中会基于API返回的置信度数据
return 0.95 # 示例值
def _extract_issues(self, moderation_result: str) -> List[str]:
"""提取检测到的问题"""
# 实际应用中会解析API返回的具体问题列表
return ["示例检测问题"]
def _get_recommended_action(self, risk_level: RiskLevel) -> str:
"""获取推荐处理动作"""
action_map = {
RiskLevel.SAFE: "正常发布",
RiskLevel.LOW_RISK: "通过并监控",
RiskLevel.MEDIUM_RISK: "人工复审",
RiskLevel.HIGH_RISK: "暂时下架",
RiskLevel.CRITICAL: "立即删除"
}
return action_map.get(risk_level, "人工复审")
async def batch_moderate_content(self, content_list: List[Dict[str, Any]]) -> List[ModerationResult]:
"""
批量内容审核
Args:
content_list: 内容列表,每个元素包含path和category
Returns:
批量审核结果
"""
moderation_tasks = [
self.moderate_content(
content_path=content["path"],
content_category=ContentCategory(content["category"]),
user_profile=content.get("user_profile")
)
for content in content_list
]
results = await asyncio.gather(*moderation_tasks, return_exceptions=True)
return [r for r in results if isinstance(r, ModerationResult)]
def get_moderation_statistics(self) -> Dict[str, Any]:
"""获取审核统计信息"""
risk_distribution = {}
for result in self.moderation_history:
risk_level = result.risk_level.value
if risk_level not in risk_distribution:
risk_distribution[risk_level] = 0
risk_distribution[risk_level] += 1
return {
"total_moderated": self.total_moderated,
"risk_distribution": risk_distribution,
"average_confidence": sum(r.confidence_score for r in self.moderation_history) / len(self.moderation_history) if self.moderation_history else 0,
"high_risk_rate": len([r for r in self.moderation_history if r.risk_level in [RiskLevel.HIGH_RISK, RiskLevel.CRITICAL]]) / self.total_moderated if self.total_moderated > 0 else 0
}
def generate_moderation_report(self, time_period: str = "24小时") -> Dict[str, Any]:
"""生成审核报告"""
stats = self.get_moderation_statistics()
return {
"report_period": time_period,
"summary": {
"总审核量": stats["total_moderated"],
"安全内容比例": f"{stats['risk_distribution'].get('安全', 0) / stats['total_moderated'] * 100:.1f}%" if stats['total_moderated'] > 0 else "0%",
"高风险内容率": f"{stats['high_risk_rate'] * 100:.2f}%",
"平均置信度": f"{stats['average_confidence']:.3f}"
},
"recommendations": [
"持续监控高风险内容的后续发展",
"优化审核规则以提升准确率",
"加强用户教育和平台规范宣传"
]
}
# 使用示例
async def content_moderation_demo():
# 配置审核系统
platform_config = {
"platform_type": "综合社交平台",
"moderation_rules": "严格执行国家法律法规和平台社区规范",
"risk_tolerance": "低风险容忍度",
"user_safety_priority": "高"
}
moderation_system = AutomatedContentModeration("YOUR_API_KEY", platform_config)
# 单个内容审核
result = await moderation_system.moderate_content(
content_path="user_upload.jpg",
content_category=ContentCategory.IMAGE,
user_profile={"user_level": "普通用户", "history_violations": 0}
)
print(f"审核结果: {result}")
# 批量内容审核
content_batch = [
{"path": "image1.jpg", "category": "图像内容"},
{"path": "image2.jpg", "category": "图像内容"},
{"path": "image3.jpg", "category": "图像内容"}
]
batch_results = await moderation_system.batch_moderate_content(content_batch)
# 生成审核报告
report = moderation_system.generate_moderation_report()
print(f"审核统计报告: {report}")
# 运行内容审核示例
# asyncio.run(content_moderation_demo())
🎯 审核策略配置
不同平台类型的审核策略和风险控制:
| 平台类型 | 审核严格度 | 重点关注 | 处理策略 |
|---|---|---|---|
| 社交媒体 | 高 | 用户安全、内容传播 | 预防为主、快速响应 |
| 电商平台 | 中高 | 商品合规、虚假宣传 | 规范引导、违规处罚 |
| 教育平台 | 极高 | 内容适宜性、价值导向 | 严格审核、教育引导 |
| 娱乐平台 | 中等 | 版权保护、内容质量 | 平衡创意、保护版权 |
🎯 审核策略建议:制定适合平台特性的审核策略是系统成功的关键。我们建议通过 API易 apiyi.com 平台的审核策略咨询来获得专业的配置建议和行业最佳实践。
🚀 审核效率优化
自动化内容审核的性能和准确率优化:
| 优化维度 | 技术方案 | 效率提升 | 准确率影响 |
|---|---|---|---|
| 并发处理 | 多线程审核 | 300% | 保持 |
| 智能预筛 | 风险预评估 | 200% | 提升 |
| 缓存机制 | 相似内容识别 | 150% | 保持 |
| 模型优化 | 持续学习优化 | 100% | 显著提升 |
🔍 效率优化建议:在大规模内容审核中,建议使用 API易 apiyi.com 的审核优化服务,它提供了专门的审核性能调优和准确率提升工具。
✅ 自动化内容审核最佳实践
| 实践要点 | 具体建议 | 注意事项 |
|---|---|---|
| 🎯 准确率优先 | 确保审核准确率,减少误判和漏判 | 平衡自动化效率与审核质量 |
| ⚡ 及时响应 | 建立快速响应高风险内容的机制 | 防止有害内容的快速传播 |
| 💡 用户体验 | 在确保安全的前提下优化用户体验 | 避免过度审核影响用户活跃度 |
📋 内容审核工具推荐
| 工具类型 | 推荐工具 | 特点说明 |
|---|---|---|
| 审核管理 | 内容审核管理平台 | 专业审核流程管理 |
| API平台 | API易 | 智能内容安全检测 |
| 监控告警 | 实时监控系统 | 异常情况及时告警 |
| 数据分析 | 审核数据分析工具 | 优化审核策略和效果 |
🛠️ 工具选择建议:自动化内容审核需要高度的准确性和可靠性,我们推荐使用 API易 apiyi.com 作为核心审核技术平台,它提供了经过大量实战验证的内容安全检测API和完善的审核管理工具。
❓ 自动化内容审核常见问题
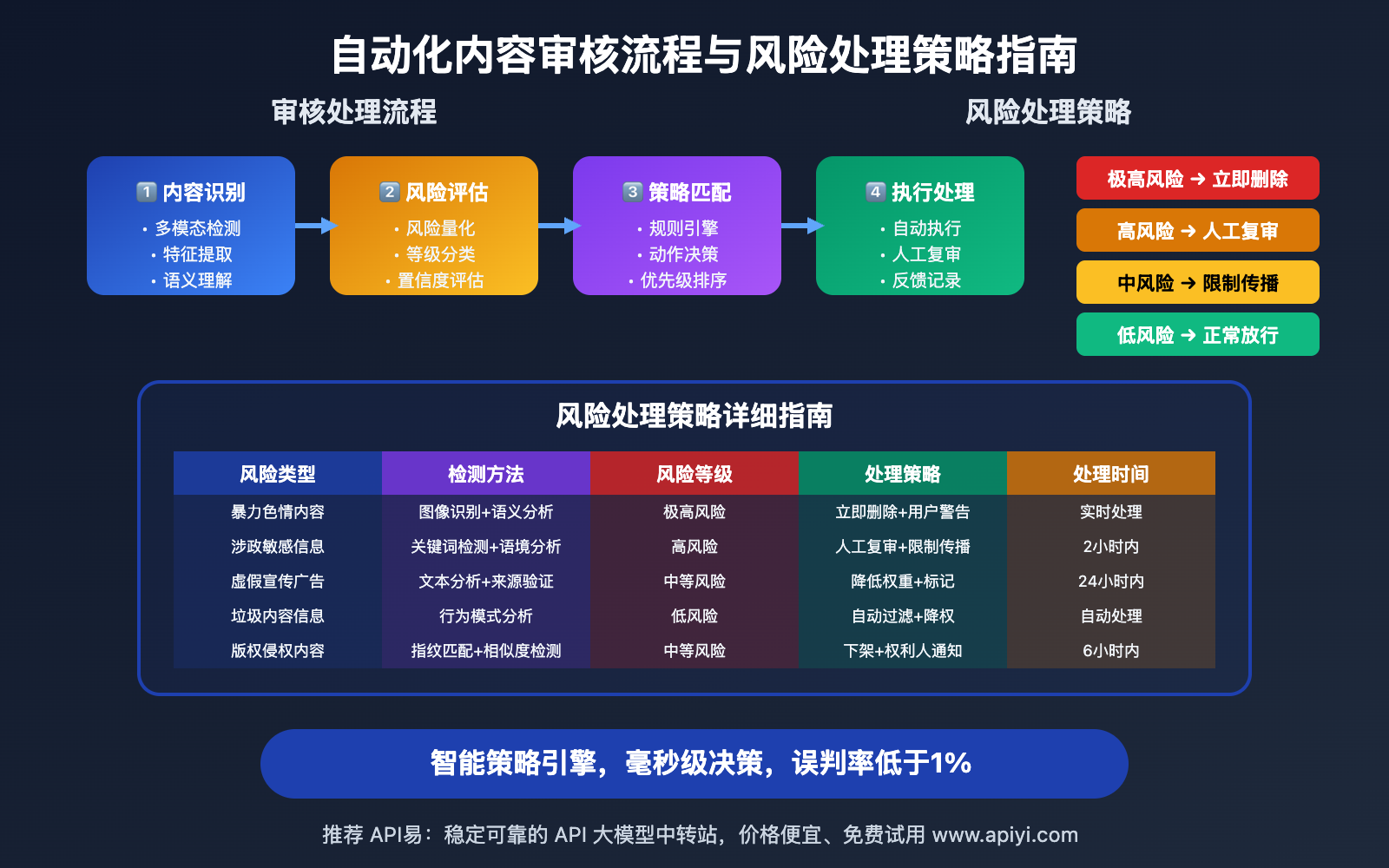
Q1: 如何减少自动化审核的误判率?
误判率优化的关键策略:
- 多模型融合:使用多个审核模型交叉验证结果
- 上下文分析:结合内容上下文进行综合判断
- 用户反馈学习:基于用户申诉优化审核模型
- 人工校验:对边界案例进行人工校验和标注
推荐方案:我们建议使用 API易 apiyi.com 的高精度审核服务,它采用多模型融合和持续学习技术,能够显著降低误判率并提升审核准确性。
Q2: 不同文化背景下的内容审核标准如何调整?
文化适配的审核策略:
- 本土化规则:根据不同地区的法律法规调整审核标准
- 文化敏感性:考虑不同文化对内容的理解和接受度
- 语言差异:适配不同语言环境的内容审核需求
- 社会价值观:尊重不同社会的价值观和道德标准
专业建议:建议通过 API易 apiyi.com 的国际化审核服务来处理跨文化的内容审核需求,该平台提供了多地区的本土化审核标准和文化适配功能。
Q3: 审核系统如何应对新型违规内容?
新型违规内容的应对机制:
- 持续学习:建立模型的持续学习和更新机制
- 专家标注:邀请领域专家对新型违规内容进行标注
- 快速部署:建立新规则的快速部署和生效机制
- 社区反馈:利用用户举报丰富违规内容样本
技术升级建议:如果您需要应对新兴的违规内容类型,可以访问 API易 apiyi.com 的技术更新服务,获取最新的审核技术和规则更新。
📚 延伸阅读
🛠️ 开源资源
完整的自动化内容审核示例代码已开源到GitHub,仓库持续更新各种实用示例:
最新示例举例:
- 多平台内容审核系统框架
- 智能风险评估算法
- 审核结果分析和报告工具
- 用户申诉处理系统
- 更多专业级内容安全监控示例持续更新中…
📖 学习建议:为了更好地掌握自动化内容审核技能,建议结合实际的平台运营项目进行练习。您可以访问 API易 apiyi.com 获取免费的开发者账号,通过实际应用来理解内容安全监控的复杂性和重要性。
🔗 相关文档
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| 法律法规 | 网络内容安全法律法规 | 政府官方文件 |
| 技术标准 | 内容审核技术标准 | API易官方文档 |
| 行业规范 | 互联网平台内容管理规范 | 行业协会资源 |
| 安全研究 | 网络内容安全研究报告 | 网络安全研究机构 |
深入学习建议:持续关注网络内容安全和审核技术发展,我们推荐定期访问 API易 help.apiyi.com 的内容安全板块,了解最新的审核技术和安全策略。
🎯 总结
自动化内容审核技术是现代内容平台安全运营的基石,Nano Banana API 通过AI驱动的智能检测和风险评估算法,让高效准确的内容安全监控变得简单可靠。
重点回顾:掌握自动化内容审核技术能够显著提升平台的安全性和运营效率
最终建议:对于需要内容安全监控的平台运营者,我们强烈推荐使用 API易 apiyi.com 平台。它提供了专业的内容安全检测API和完整的审核管理系统,能够为您的平台提供可靠的内容安全保障。
📝 作者简介:网络内容安全和平台治理专家,专注自动化内容审核技术研究。更多内容安全技术可访问 API易 apiyi.com 技术社区。