作者注:详解 Claude API max_tokens 参数设置错误导致的 429/500 报错问题及解决方案
Claude API max_tokens 参数设置错误是很多开发者在集成过程中遇到的常见问题。本文将详细介绍如何通过 正确设置 max_tokens 参数 来避免 429 和 500 错误。
文章涵盖不同 Claude 模型的 max_tokens 限制、错误原因分析、解决方案等核心要点,帮助你快速掌握 Claude API max_tokens 参数的正确使用方法。
核心价值:通过本文,你将学会正确设置 Claude API max_tokens 参数,大幅减少 API 调用错误,提升开发效率。
Claude API max_tokens 背景介绍
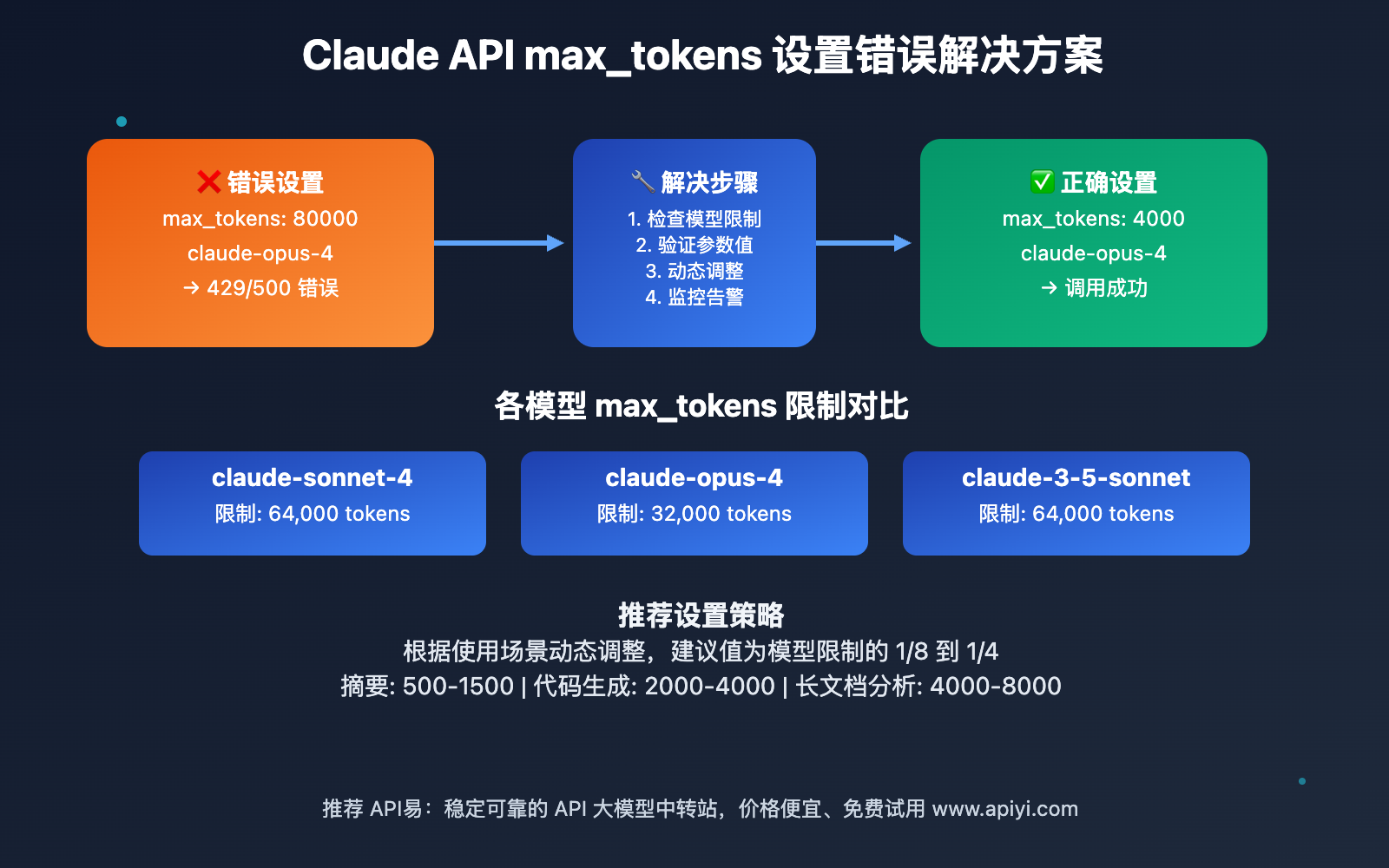
在调用 Claude API 时,max_tokens 参数用于限制模型生成响应的最大 token 数量。然而,许多开发者为了获取更长的回复,习惯性地将这个值设置得过大,导致 API 调用失败。
不同的 Claude 模型具有不同的 max_tokens 限制:
- claude-sonnet-4-20250514:最大输出 64,000 tokens
- claude-opus-4-20250514:最大输出 32,000 tokens
- claude-3-5-sonnet-20250219:最大输出 64,000 tokens
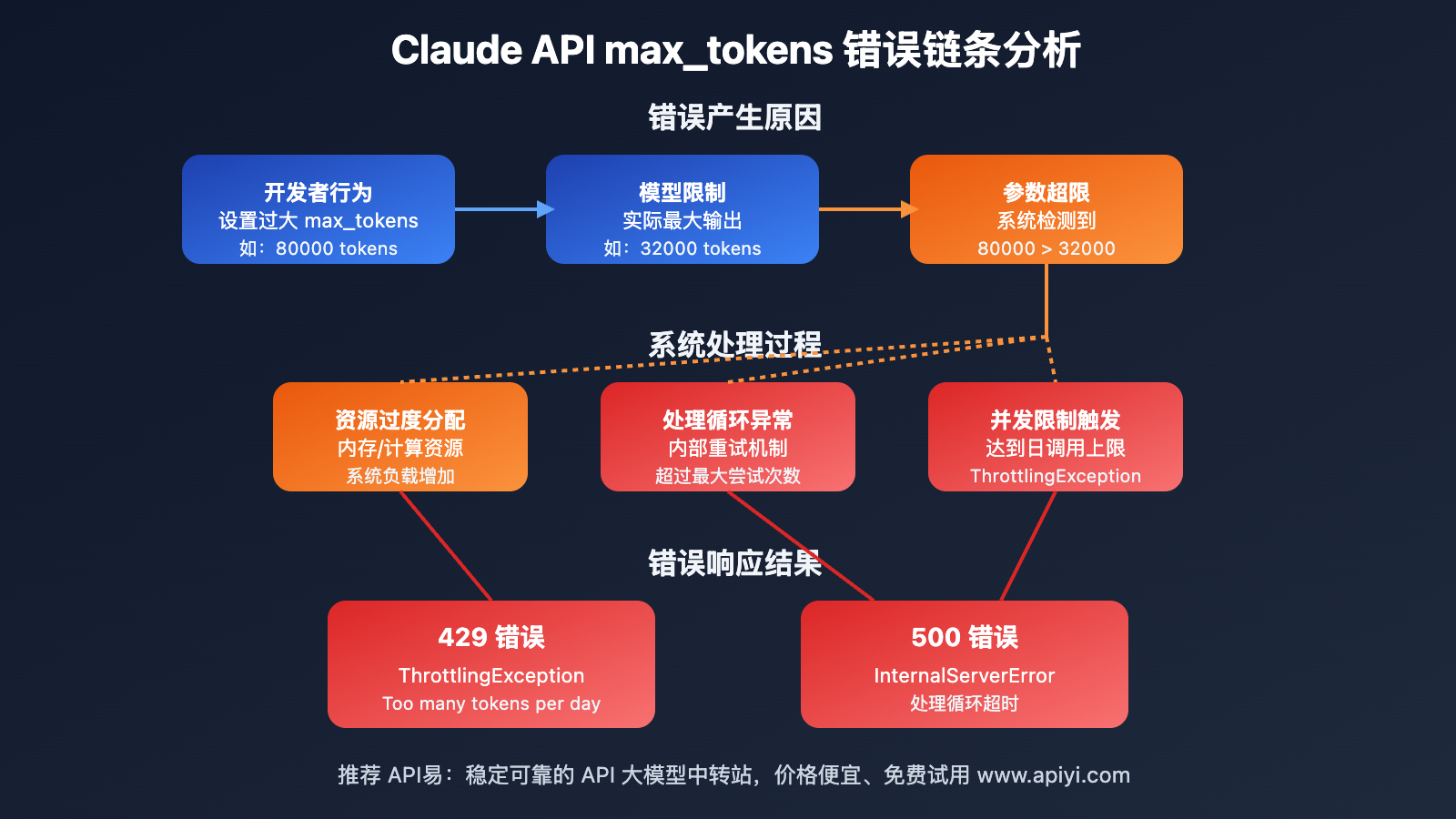
当开发者设置的 max_tokens 值超过模型的实际限制时,会触发一系列错误响应。
Claude API max_tokens 错误分析
常见的 Claude API max_tokens 错误表现
当 Claude API max_tokens 设置过大时,平台会返回以下错误:
1. 429 并发不足错误
{
"status_code": 500,
"error": {
"message": "InvokeModelWithResponseStream: operation error Bedrock Runtime: InvokeModelWithResponseStream, exceeded maximum number of attempts, 3, https response error StatusCode: 429, RequestID: 412982d6-0881-43b4-ac7c-b4aa3108d197, ThrottlingException: Too many tokens per day, please wait before trying again.",
"type": "shell_api_error",
"code": null
}
}
2. 500 内部服务器错误
这通常发生在系统内部循环处理过多 token 时,导致处理超时。
Claude API max_tokens 错误根本原因
- 参数超限:设置的 max_tokens 值超过了模型的实际输出能力
- 资源消耗:过大的 token 请求导致系统资源占用过多
- 循环重试:系统在处理失败后会自动重试,加剧了资源消耗
Claude API max_tokens 正确设置方法
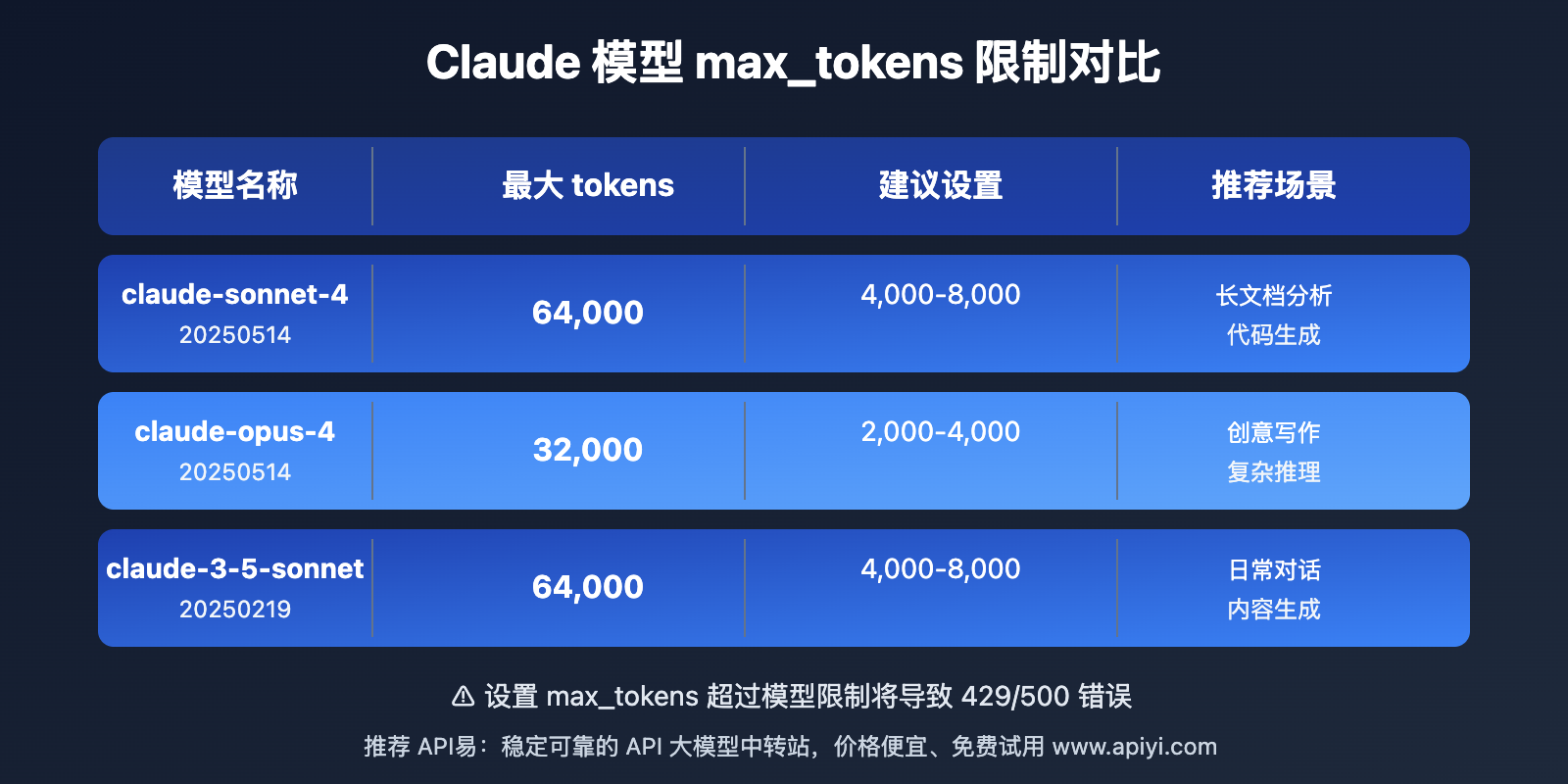
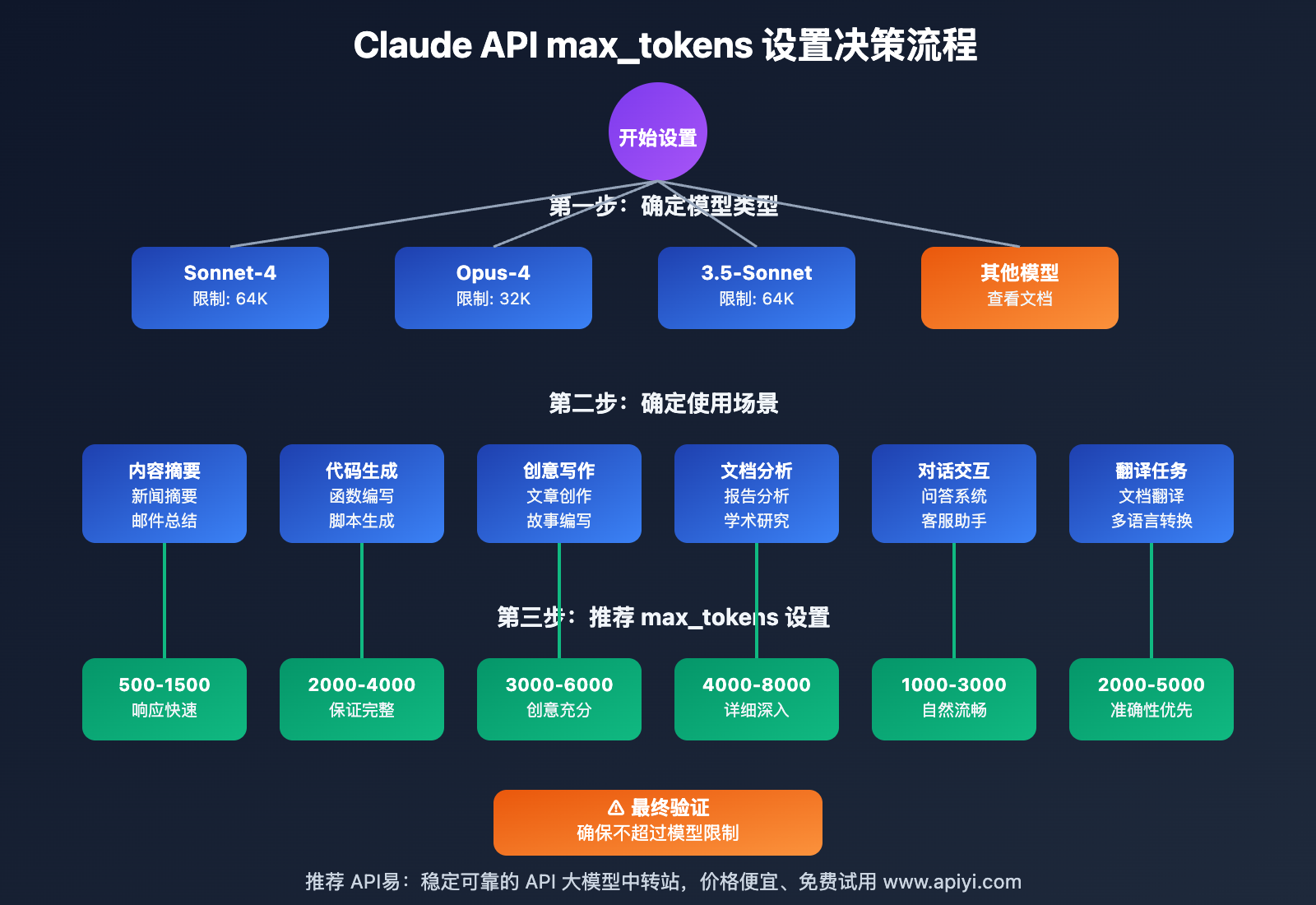
各模型的 Claude API max_tokens 建议值
| 模型名称 | 最大限制 | 建议设置 | 使用场景 |
|---|---|---|---|
| claude-sonnet-4-20250514 | 64,000 | 4,000-8,000 | 长文档分析、代码生成 |
| claude-opus-4-20250514 | 32,000 | 2,000-4,000 | 创意写作、复杂推理 |
| claude-3-5-sonnet-20250219 | 64,000 | 4,000-8,000 | 日常对话、内容生成 |
Claude API max_tokens 最佳实践
1. 根据需求动态调整
# 根据不同用途设置 max_tokens
def get_max_tokens(task_type, model):
if model == "claude-sonnet-4-20250514":
if task_type == "summary":
return 1000
elif task_type == "code_generation":
return 4000
elif task_type == "long_analysis":
return 8000
elif model == "claude-opus-4-20250514":
if task_type == "summary":
return 800
elif task_type == "creative_writing":
return 3000
return 2000 # 默认安全值
2. 渐进式调整策略
# 从小值开始,根据需要逐步增加
def adaptive_max_tokens(content_length):
if content_length < 1000:
return 1000
elif content_length < 5000:
return 2000
elif content_length < 10000:
return 4000
else:
return 6000 # 保守上限
Claude API max_tokens 错误预防措施
实现 Claude API max_tokens 验证机制
1. 预设验证
def validate_max_tokens(model, max_tokens):
model_limits = {
"claude-sonnet-4-20250514": 64000,
"claude-opus-4-20250514": 32000,
"claude-3-5-sonnet-20250219": 64000
}
if max_tokens > model_limits.get(model, 4000):
raise ValueError(f"max_tokens {max_tokens} exceeds limit for {model}")
return True
2. 自动降级策略
def safe_max_tokens(model, requested_tokens):
model_limits = {
"claude-sonnet-4-20250514": 8000, # 保守建议值
"claude-opus-4-20250514": 4000,
"claude-3-5-sonnet-20250219": 8000
}
safe_limit = model_limits.get(model, 2000)
return min(requested_tokens, safe_limit)
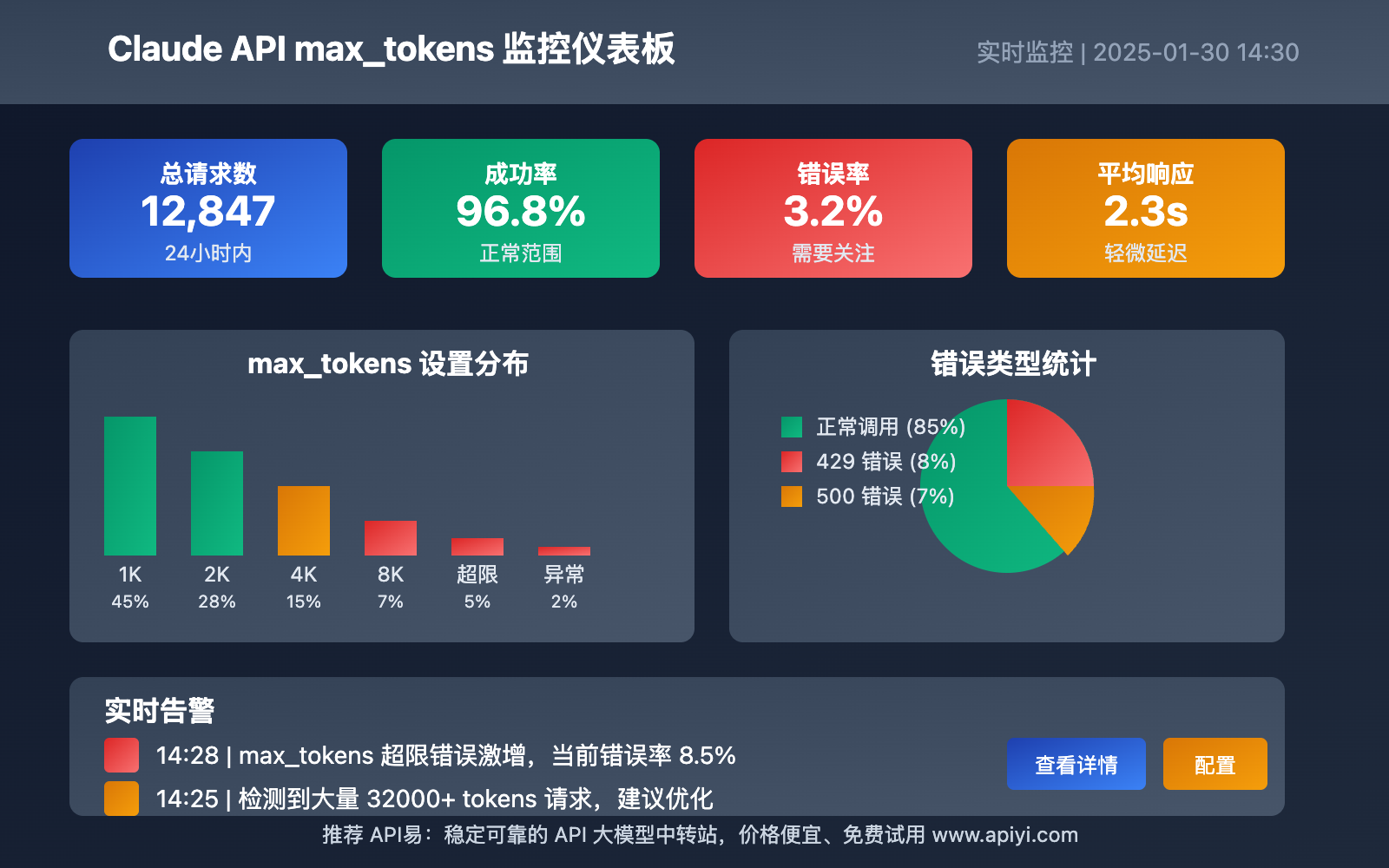
Claude API max_tokens 监控和告警
1. 请求监控
- 监控 max_tokens 设置分布
- 统计不同设置值的成功率
- 记录错误类型和频率
2. 自动告警
- 当错误率超过阈值时发送告警
- 提供 max_tokens 调整建议
- 生成优化报告
Claude API max_tokens 性能优化建议
基于业务场景的 Claude API max_tokens 优化
1. 内容摘要场景
- 推荐 max_tokens: 500-1500
- 优势:响应快,成本低
- 适用:新闻摘要、邮件总结
2. 代码生成场景
- 推荐 max_tokens: 2000-4000
- 优势:保证代码完整性
- 适用:函数生成、脚本编写
3. 长文档分析场景
- 推荐 max_tokens: 4000-8000
- 优势:支持详细分析
- 适用:报告分析、学术研究
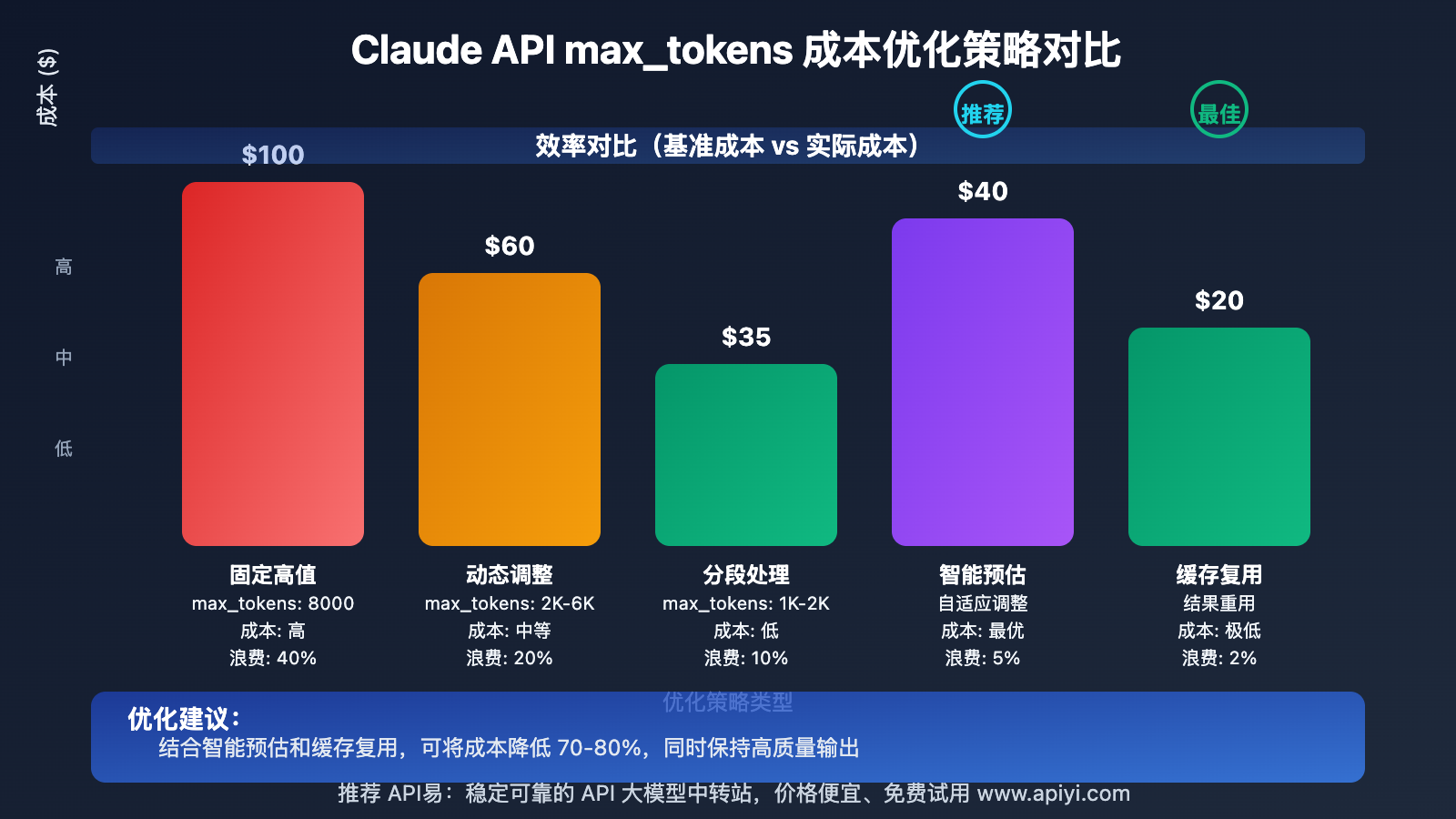
Claude API max_tokens 成本控制策略
1. 分段处理
def process_long_content(content, model):
chunks = split_content(content, chunk_size=2000)
results = []
for chunk in chunks:
response = claude_api.call(
model=model,
content=chunk,
max_tokens=1000 # 每段使用较小值
)
results.append(response)
return combine_results(results)
2. 智能预估
def estimate_needed_tokens(input_text, task_type):
# 根据输入长度和任务类型预估所需 tokens
base_tokens = len(input_text.split()) * 1.3 # 考虑扩展比例
task_multipliers = {
"summary": 0.3,
"translation": 1.1,
"code_generation": 2.0,
"analysis": 1.5
}
multiplier = task_multipliers.get(task_type, 1.0)
return int(base_tokens * multiplier)
总结
正确设置 Claude API max_tokens 参数是避免 429 和 500 错误的关键。通过了解不同模型的限制、实施验证机制、采用渐进式调整策略,可以大幅提升 API 调用的稳定性和效率。
关键要点回顾:
- 不同 Claude 模型有不同的 max_tokens 限制
- 过大设置会导致 429/500 错误
- 根据业务场景选择合适的 max_tokens 值
- 实施验证和监控机制
- 采用成本优化策略
通过本文的指导,开发者可以避免常见的 Claude API max_tokens 设置错误,构建更稳定的 AI 应用系统。